I am newbie to Apache Spark.
My job is read two CSV files, select some specific columns from it, merge it, aggregate it and write the result into a single CSV file.
For example,
CSV1
name,age,deparment_id
CSV2
department_id,deparment_name,location
I want to get a third CSV file with
name,age,deparment_name
I am loading both the CSV into dataframes.
And then able to get the third dataframe using several methods join,select,filter,drop present in dataframe
I am also able to do the same using several RDD.map()
And I am also able to do the same using executing hiveql using HiveContext
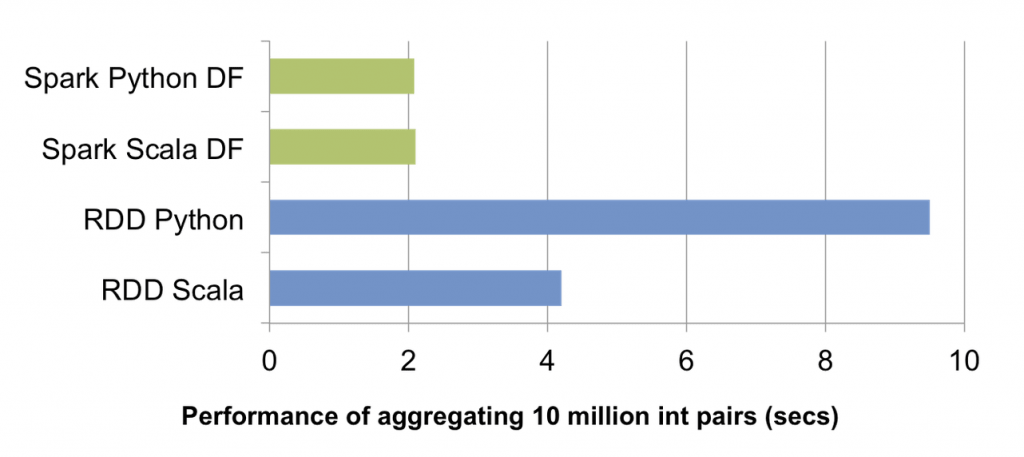
I want to know which is the efficient way if my CSV files are huge and why?
{kind=link}