There should be something akin to \w that can match any code-point in Letters or Marks category (not just the ASCII ones), and hopefully have filters like [[P*]] for punctuation, etc.
Asked
Active
Viewed 1.8e+01k times
258
Braiam
- 1
- 11
- 47
- 78
-
This doesn't include regular expression support but is useful for Unicode related tasks https://github.com/joelarson4/CharFunk – jwl Mar 23 '13 at 16:19
11 Answers
227
Situation for ES 6
The ECMAScript language specification, edition 6 (also commonly known as ES2015), includes Unicode-aware regular expressions. Support must be enabled with the u modifier on the regex. See Unicode-aware regular expressions in ES6 for a break-down of the feature and some caveats.
ES6 is widely adopted in both browsers and stand-alone Javascript runtimes such as Node.js, so using this feature won't require extra effort in most cases. Full compatibility list: https://kangax.github.io/compat-table/es6/
Situation for ES 5 and below (legacy browsers)
There is a transpiler named regexpu that translates ES6 Unicode regular expressions into equivalent ES5. It can be used as part of your build process. Try it out online..
Even though JavaScript operates on Unicode strings, it does not implement Unicode-aware character classes and has no concept of POSIX character classes or Unicode blocks/sub-ranges.
Check your expectations here: Javascript RegExp Unicode Character Class tester (Edit: the original page is down, the Internet Archive still has a copy.)
Flagrant Badassery has an article on JavaScript, Regex, and Unicode that sheds some light on the matter.
Also read Regex and Unicode here on SO. Probably you have to build your own "punctuation character class".
Check out the Regular Expression: Match Unicode Block Range builder (archived copy), which lets you build a JavaScript regular expression that matches characters that fall in any number of specified Unicode blocks.
I just did it for the "General Punctuation" and "Supplemental Punctuation" sub-ranges, and the result is as simple and straight-forward as I would have expected it:
[\u2000-\u206F\u2E00-\u2E7F]There also is XRegExp, a project that brings Unicode support to JavaScript by offering an alternative regex engine with extended capabilities.
And of course, required reading: mathiasbynens.be - JavaScript has a Unicode problem:
Tomalak
- 332,285
- 67
- 532
- 628
-
5This last tool is great for blocks, but does little when what you want are character types scattered through many blocks (like letters or numbers). See [this](http://stackoverflow.com/a/8933546/520779) for a similar approach for this case. – mgibsonbr Feb 01 '12 at 22:09
-
1[6to5](http://6to5.org/) and [traceur](https://github.com/google/traceur-compiler) also [support](http://kangax.github.io/compat-table/es6/) the `u` flag as well as some other [ES6 features](https://github.com/lukehoban/es6features#user-content-unicode) for working with Unicode. – Useless Code Jan 24 '15 at 00:09
-
2@UselessCode Yeah, Babel and Traceur use _regexpu_ as a dependency to transpile those `u` regular expressions. – Mathias Bynens Jun 10 '16 at 08:07
-
1If you need unicode character classes like \pL and support for old browsers, then the XRegExp library (see the proprietary A flag there) is definitely a smooth solution. Thanks! – BurninLeo Nov 25 '16 at 11:10
-
1Unfortunately the online transpiler did not work for me using \w with a Chinese character. Tried to transpile ```"a品cd!e f".replace(/[^\w]/ug, "")``` and but the resulting regex (run in Chrome 59) still removes the ```品```character and only returns ```"acdef"``` – mwag Jul 07 '17 at 20:02
-
@mwag ES6 is still not default in browsers. Please post a separate question, you already have all the parts that are necessary. If possible link back the answer here, so I can update this post. – Tomalak Jul 07 '17 at 20:43
-
@Tomalak I was not trying to run ES6 but rather ES5 which is why I tried the transpiler. ```"a品cd!e f".replace(/[^\w]/ug, "")``` transpiles to ES5 ```"a品cd!e f".replace(/(?:[\0-/:-@\[-\^`\{-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF])/g, "")``` which incorrectly results in "acdef" – mwag Jul 07 '17 at 20:47
-
That's excellent material for a separate question. You did all the homework. I am on mobile for the time being, I can’t do much more than write comments. Please open a separate thread. – Tomalak Jul 07 '17 at 21:03
-
Just saying, never use `\w` it has a different meaning based on env locale. Prefer `\\pL` from [XRegExp](http://xregexp.com/plugins/#unicode) library – Antoine Jul 24 '17 at 13:02
-
1You mean the input validation attribute in form fields? It uses the same regex as built into the given browser's JS engine, and it's compiled with flags disabled ([see this answer](https://stackoverflow.com/questions/5524842/have-html5s-a-inputs-pattern-attribute-ignore-case)). I assume that this would inlcude the `u` flag, even if it were supported, but I'm not 100% sure. It would make good stand-alone question to ask here, although you can just easily find out by experimentation. – Tomalak Oct 07 '19 at 06:13
-
I think this answer misses the question. The question, as I understand it, is how to have a unicode-aware of saying e.g. `/\w/.test('ö')` where ö is a non-ASCII letter. See the answer by Kamil Kiełczewski below: `/\p{L}/u.test('ö')`. – Michael Sep 05 '22 at 11:11
-
@Michael `/u` did not exist when this answer was written originally. And there is an edit right on the top of the answer that mentions that Unicode is directly supported in modern JS. – Tomalak Sep 05 '22 at 17:19
76
Personally, I would rather not install another library just to get this functionality. My answer does not require any external libraries, and it may also work with little modification for regex flavors besides JavaScript.
Unicode's website provides a way to translate Unicode categories into a set of code points. Since it's Unicode's website, the information from it should be accurate.
Note that you will need to exclude the high-end characters, as JavaScript can only handle characters less than FFFF (hex). I suggest checking the Abbreviate Collate, and Escape check boxes, which strike a balance between avoiding unprintable characters and minimizing the size of the regex.
Here are some common expansions of different Unicode properties:
\p{L} (Letters):
[A-Za-z\u00AA\u00B5\u00BA\u00C0-\u00D6\u00D8-\u00F6\u00F8-\u02C1\u02C6-\u02D1\u02E0-\u02E4\u02EC\u02EE\u0370-\u0374\u0376\u0377\u037A-\u037D\u037F\u0386\u0388-\u038A\u038C\u038E-\u03A1\u03A3-\u03F5\u03F7-\u0481\u048A-\u052F\u0531-\u0556\u0559\u0561-\u0587\u05D0-\u05EA\u05F0-\u05F2\u0620-\u064A\u066E\u066F\u0671-\u06D3\u06D5\u06E5\u06E6\u06EE\u06EF\u06FA-\u06FC\u06FF\u0710\u0712-\u072F\u074D-\u07A5\u07B1\u07CA-\u07EA\u07F4\u07F5\u07FA\u0800-\u0815\u081A\u0824\u0828\u0840-\u0858\u08A0-\u08B4\u0904-\u0939\u093D\u0950\u0958-\u0961\u0971-\u0980\u0985-\u098C\u098F\u0990\u0993-\u09A8\u09AA-\u09B0\u09B2\u09B6-\u09B9\u09BD\u09CE\u09DC\u09DD\u09DF-\u09E1\u09F0\u09F1\u0A05-\u0A0A\u0A0F\u0A10\u0A13-\u0A28\u0A2A-\u0A30\u0A32\u0A33\u0A35\u0A36\u0A38\u0A39\u0A59-\u0A5C\u0A5E\u0A72-\u0A74\u0A85-\u0A8D\u0A8F-\u0A91\u0A93-\u0AA8\u0AAA-\u0AB0\u0AB2\u0AB3\u0AB5-\u0AB9\u0ABD\u0AD0\u0AE0\u0AE1\u0AF9\u0B05-\u0B0C\u0B0F\u0B10\u0B13-\u0B28\u0B2A-\u0B30\u0B32\u0B33\u0B35-\u0B39\u0B3D\u0B5C\u0B5D\u0B5F-\u0B61\u0B71\u0B83\u0B85-\u0B8A\u0B8E-\u0B90\u0B92-\u0B95\u0B99\u0B9A\u0B9C\u0B9E\u0B9F\u0BA3\u0BA4\u0BA8-\u0BAA\u0BAE-\u0BB9\u0BD0\u0C05-\u0C0C\u0C0E-\u0C10\u0C12-\u0C28\u0C2A-\u0C39\u0C3D\u0C58-\u0C5A\u0C60\u0C61\u0C85-\u0C8C\u0C8E-\u0C90\u0C92-\u0CA8\u0CAA-\u0CB3\u0CB5-\u0CB9\u0CBD\u0CDE\u0CE0\u0CE1\u0CF1\u0CF2\u0D05-\u0D0C\u0D0E-\u0D10\u0D12-\u0D3A\u0D3D\u0D4E\u0D5F-\u0D61\u0D7A-\u0D7F\u0D85-\u0D96\u0D9A-\u0DB1\u0DB3-\u0DBB\u0DBD\u0DC0-\u0DC6\u0E01-\u0E30\u0E32\u0E33\u0E40-\u0E46\u0E81\u0E82\u0E84\u0E87\u0E88\u0E8A\u0E8D\u0E94-\u0E97\u0E99-\u0E9F\u0EA1-\u0EA3\u0EA5\u0EA7\u0EAA\u0EAB\u0EAD-\u0EB0\u0EB2\u0EB3\u0EBD\u0EC0-\u0EC4\u0EC6\u0EDC-\u0EDF\u0F00\u0F40-\u0F47\u0F49-\u0F6C\u0F88-\u0F8C\u1000-\u102A\u103F\u1050-\u1055\u105A-\u105D\u1061\u1065\u1066\u106E-\u1070\u1075-\u1081\u108E\u10A0-\u10C5\u10C7\u10CD\u10D0-\u10FA\u10FC-\u1248\u124A-\u124D\u1250-\u1256\u1258\u125A-\u125D\u1260-\u1288\u128A-\u128D\u1290-\u12B0\u12B2-\u12B5\u12B8-\u12BE\u12C0\u12C2-\u12C5\u12C8-\u12D6\u12D8-\u1310\u1312-\u1315\u1318-\u135A\u1380-\u138F\u13A0-\u13F5\u13F8-\u13FD\u1401-\u166C\u166F-\u167F\u1681-\u169A\u16A0-\u16EA\u16F1-\u16F8\u1700-\u170C\u170E-\u1711\u1720-\u1731\u1740-\u1751\u1760-\u176C\u176E-\u1770\u1780-\u17B3\u17D7\u17DC\u1820-\u1877\u1880-\u18A8\u18AA\u18B0-\u18F5\u1900-\u191E\u1950-\u196D\u1970-\u1974\u1980-\u19AB\u19B0-\u19C9\u1A00-\u1A16\u1A20-\u1A54\u1AA7\u1B05-\u1B33\u1B45-\u1B4B\u1B83-\u1BA0\u1BAE\u1BAF\u1BBA-\u1BE5\u1C00-\u1C23\u1C4D-\u1C4F\u1C5A-\u1C7D\u1CE9-\u1CEC\u1CEE-\u1CF1\u1CF5\u1CF6\u1D00-\u1DBF\u1E00-\u1F15\u1F18-\u1F1D\u1F20-\u1F45\u1F48-\u1F4D\u1F50-\u1F57\u1F59\u1F5B\u1F5D\u1F5F-\u1F7D\u1F80-\u1FB4\u1FB6-\u1FBC\u1FBE\u1FC2-\u1FC4\u1FC6-\u1FCC\u1FD0-\u1FD3\u1FD6-\u1FDB\u1FE0-\u1FEC\u1FF2-\u1FF4\u1FF6-\u1FFC\u2071\u207F\u2090-\u209C\u2102\u2107\u210A-\u2113\u2115\u2119-\u211D\u2124\u2126\u2128\u212A-\u212D\u212F-\u2139\u213C-\u213F\u2145-\u2149\u214E\u2183\u2184\u2C00-\u2C2E\u2C30-\u2C5E\u2C60-\u2CE4\u2CEB-\u2CEE\u2CF2\u2CF3\u2D00-\u2D25\u2D27\u2D2D\u2D30-\u2D67\u2D6F\u2D80-\u2D96\u2DA0-\u2DA6\u2DA8-\u2DAE\u2DB0-\u2DB6\u2DB8-\u2DBE\u2DC0-\u2DC6\u2DC8-\u2DCE\u2DD0-\u2DD6\u2DD8-\u2DDE\u2E2F\u3005\u3006\u3031-\u3035\u303B\u303C\u3041-\u3096\u309D-\u309F\u30A1-\u30FA\u30FC-\u30FF\u3105-\u312D\u3131-\u318E\u31A0-\u31BA\u31F0-\u31FF\u3400-\u4DB5\u4E00-\u9FD5\uA000-\uA48C\uA4D0-\uA4FD\uA500-\uA60C\uA610-\uA61F\uA62A\uA62B\uA640-\uA66E\uA67F-\uA69D\uA6A0-\uA6E5\uA717-\uA71F\uA722-\uA788\uA78B-\uA7AD\uA7B0-\uA7B7\uA7F7-\uA801\uA803-\uA805\uA807-\uA80A\uA80C-\uA822\uA840-\uA873\uA882-\uA8B3\uA8F2-\uA8F7\uA8FB\uA8FD\uA90A-\uA925\uA930-\uA946\uA960-\uA97C\uA984-\uA9B2\uA9CF\uA9E0-\uA9E4\uA9E6-\uA9EF\uA9FA-\uA9FE\uAA00-\uAA28\uAA40-\uAA42\uAA44-\uAA4B\uAA60-\uAA76\uAA7A\uAA7E-\uAAAF\uAAB1\uAAB5\uAAB6\uAAB9-\uAABD\uAAC0\uAAC2\uAADB-\uAADD\uAAE0-\uAAEA\uAAF2-\uAAF4\uAB01-\uAB06\uAB09-\uAB0E\uAB11-\uAB16\uAB20-\uAB26\uAB28-\uAB2E\uAB30-\uAB5A\uAB5C-\uAB65\uAB70-\uABE2\uAC00-\uD7A3\uD7B0-\uD7C6\uD7CB-\uD7FB\uF900-\uFA6D\uFA70-\uFAD9\uFB00-\uFB06\uFB13-\uFB17\uFB1D\uFB1F-\uFB28\uFB2A-\uFB36\uFB38-\uFB3C\uFB3E\uFB40\uFB41\uFB43\uFB44\uFB46-\uFBB1\uFBD3-\uFD3D\uFD50-\uFD8F\uFD92-\uFDC7\uFDF0-\uFDFB\uFE70-\uFE74\uFE76-\uFEFC\uFF21-\uFF3A\uFF41-\uFF5A\uFF66-\uFFBE\uFFC2-\uFFC7\uFFCA-\uFFCF\uFFD2-\uFFD7\uFFDA-\uFFDC]
\p{Nd} (Number decimal digits):
[0-9\u0660-\u0669\u06F0-\u06F9\u07C0-\u07C9\u0966-\u096F\u09E6-\u09EF\u0A66-\u0A6F\u0AE6-\u0AEF\u0B66-\u0B6F\u0BE6-\u0BEF\u0C66-\u0C6F\u0CE6-\u0CEF\u0D66-\u0D6F\u0DE6-\u0DEF\u0E50-\u0E59\u0ED0-\u0ED9\u0F20-\u0F29\u1040-\u1049\u1090-\u1099\u17E0-\u17E9\u1810-\u1819\u1946-\u194F\u19D0-\u19D9\u1A80-\u1A89\u1A90-\u1A99\u1B50-\u1B59\u1BB0-\u1BB9\u1C40-\u1C49\u1C50-\u1C59\uA620-\uA629\uA8D0-\uA8D9\uA900-\uA909\uA9D0-\uA9D9\uA9F0-\uA9F9\uAA50-\uAA59\uABF0-\uABF9\uFF10-\uFF19]
\p{P} (Punctuation):
[!-#%-*,-/\:;?@\[-\]_\{\}\u00A1\u00A7\u00AB\u00B6\u00B7\u00BB\u00BF\u037E\u0387\u055A-\u055F\u0589\u058A\u05BE\u05C0\u05C3\u05C6\u05F3\u05F4\u0609\u060A\u060C\u060D\u061B\u061E\u061F\u066A-\u066D\u06D4\u0700-\u070D\u07F7-\u07F9\u0830-\u083E\u085E\u0964\u0965\u0970\u0AF0\u0DF4\u0E4F\u0E5A\u0E5B\u0F04-\u0F12\u0F14\u0F3A-\u0F3D\u0F85\u0FD0-\u0FD4\u0FD9\u0FDA\u104A-\u104F\u10FB\u1360-\u1368\u1400\u166D\u166E\u169B\u169C\u16EB-\u16ED\u1735\u1736\u17D4-\u17D6\u17D8-\u17DA\u1800-\u180A\u1944\u1945\u1A1E\u1A1F\u1AA0-\u1AA6\u1AA8-\u1AAD\u1B5A-\u1B60\u1BFC-\u1BFF\u1C3B-\u1C3F\u1C7E\u1C7F\u1CC0-\u1CC7\u1CD3\u2010-\u2027\u2030-\u2043\u2045-\u2051\u2053-\u205E\u207D\u207E\u208D\u208E\u2308-\u230B\u2329\u232A\u2768-\u2775\u27C5\u27C6\u27E6-\u27EF\u2983-\u2998\u29D8-\u29DB\u29FC\u29FD\u2CF9-\u2CFC\u2CFE\u2CFF\u2D70\u2E00-\u2E2E\u2E30-\u2E42\u3001-\u3003\u3008-\u3011\u3014-\u301F\u3030\u303D\u30A0\u30FB\uA4FE\uA4FF\uA60D-\uA60F\uA673\uA67E\uA6F2-\uA6F7\uA874-\uA877\uA8CE\uA8CF\uA8F8-\uA8FA\uA8FC\uA92E\uA92F\uA95F\uA9C1-\uA9CD\uA9DE\uA9DF\uAA5C-\uAA5F\uAADE\uAADF\uAAF0\uAAF1\uABEB\uFD3E\uFD3F\uFE10-\uFE19\uFE30-\uFE52\uFE54-\uFE61\uFE63\uFE68\uFE6A\uFE6B\uFF01-\uFF03\uFF05-\uFF0A\uFF0C-\uFF0F\uFF1A\uFF1B\uFF1F\uFF20\uFF3B-\uFF3D\uFF3F\uFF5B\uFF5D\uFF5F-\uFF65]
The page also recognizes a number of obscure character classes, such as \p{Hira}, which is just the (Japanese) Hiragana characters:
[\u3041-\u3096\u309D-\u309F]
Lastly, it's possible to plug a char class with more than one Unicode property to get a shorter regex than you would get by just combining them (as long as certain settings are checked).
Laurel
- 5,965
- 14
- 31
- 57
-
`\p`-Syntax does not seem to work in JS, `/\p{L}/.test('a')` is `false` – Dmitri Zaitsev Apr 18 '17 at 07:26
-
2@DmitriZaitsev Of course it doesn't. You will need to use the "expansion" which I listed underneath. – Laurel Apr 18 '17 at 15:16
-
The "expansion" with horizontal scrollbar 1/100 of the line? In production code with unit tests? ;) – Dmitri Zaitsev Apr 18 '17 at 16:55
-
Perhaps you could mention more explicitly which ones work with JS and which don't, to improve the clarity. – Dmitri Zaitsev Apr 18 '17 at 16:59
-
3@DmitriZaitsev I think you may be missing the point here, he's provided a set of regex's which all work in JS. Since they are substituting for what should (and will) be native functionality, they're necessarily pretty long. How would you unit test the native functionality? – HeyHeyJC May 03 '17 at 23:15
-
@HeyHeyJC Actually not all works in JS, the `\p` doesn't as confirmed in comment above. And you are not testing the native function but the long regex. How else can you be sure it works as expected? – Dmitri Zaitsev May 04 '17 at 04:34
-
@Laurel the unicodes under \p{L} (Letters) are you saying it works same as \P{L} in PHP like coves all characters in all languages? If yes are there no characters in 5 digit unicodes that cover different language alphabetic characters. I have seen some unicodes like \u{E007F} which covers 5 digit unicodes – Labeo Jun 06 '17 at 08:54
-
Ö character is not matching when I used your \p{L} (Letters) unicode example in my test suite. I had to add \u0308. I don't understand why the existing code didn't work. Not sure if what I've done adds a side effect. – Learner Oct 24 '20 at 13:30
-
2@DmitriZaitsev you lack the `/u` modifier, you should write `/\p{L}/u.test('a')` – Yvan Aug 17 '22 at 15:48
-
1
58
Having also not found a good solution, I wrote a small script a long time ago, by downloading data from the unicode specification (v.5.0.0) and generating intervals for each unicode category and subcategory in the BMP (lately replaced by a small Java program that uses its own native Unicode support).
Basically it converts \p{...} to a range of values, much like the output of the tool mentioned by Tomalak, but the intervals can end up quite large (since it's not dealing with blocks, but with characters scattered through many different places).
For instance, a Regex written like this:
var regex = unicode_hack(/\p{L}(\p{L}|\p{Nd})*/g);
Will be converted to something like this:
/[\u0041-\u005a\u0061-\u007a...]([...]|[\u0030-\u0039\u0660-\u0669...])*/g
Haven't used it a lot in practice, but it seems to work fine from my tests, so I'm posting here in case someone find it useful. Despite the length of the resulting regexes (the example above has 3591 characters when expanded), the performance seems to be acceptable (see the tests at jsFiddle; thanks to @modiX and @Lwangaman for the improvements).
Here's the source (raw, 27.5KB; minified, 24.9KB, not much better...). It might be made smaller by unescaping the unicode characters, but OTOH will run the risk of encoding issues, so I'm leaving as it is. Hopefully with ES6 this kind of thing won't be necessary anymore.
Update: this looks like the same strategy adopted in the XRegExp Unicode plug-in mentioned by Tim Down, except that in this case regular JavaScript regexes are being used.
mgibsonbr
- 21,755
- 7
- 70
- 112
-
1I used your script to solve my issue (http://stackoverflow.com/questions/23391573/client-side-validation-including-unicode-character-ranges/23413201) but your unicode ranges do not include Taiwan, Chinese or Japanese characters. so `/^\p{L}+$/` should match `東海林` but it does not. Whenever you update the collection, please inform me. Thanks a lot. – Martin Braun May 01 '14 at 19:57
-
2Ok it's simple. Taiwan, Chinese and Japagnese using this unicode table: http://www.rikai.com/library/kanjitables/kanji_codes.unicode.shtml While you got the Katakana table in `\p{Lo}`, you miss the both Kanji tables in it. – Martin Braun May 01 '14 at 21:13
-
@modiX Thanks for pointing that out! I updated the script, this time using Java to [generate the list](https://ideone.com/04llh4) - instead of scrapping them from the Unicode files. I plan on adding support for the SMPs as well, if feasible. – mgibsonbr May 04 '14 at 09:04
-
Thanks for this. Wheee, looking on the supplementary multilingual plane of unicode there is a lot that needs to be done, didn't know it's not included yet. Please keep me informed when adding those to your current Java program (output). – Martin Braun May 05 '14 at 09:53
-
@modiX Unfortunatly I found out that JavaScript regexes can't handle character intervals outside BMP ([example](http://jsfiddle.net/mgibsonbr/vE2Rj/)). Since that's a key point in my implementation, that means I won't be able to add proper support for SMP, ever! :( My solution is thus restricted to BMP for the time being, let's hope EcmaScript 6 makes things better... – mgibsonbr May 06 '14 at 09:43
-
looks like a handy script, do you think you could add the "\p{L&}" modifier to it? This should match any character that has a corresponding uppercase or lowercase counterpart. – JohnRDOrazio Jan 10 '15 at 16:42
-
@Lwangaman I guess I could, but is this standard? Never seen it before... Do you have any reference I can take a look at (regardless of language)? – mgibsonbr Jan 10 '15 at 17:41
-
1I have added it in the JSFiddle example (and got the ul's and li's to render correctly): http://jsfiddle.net/Waxkc/49/ You can find a reference to the \p{L&} modifier here: http://www.regular-expressions.info/unicode.html I've been using it in my own scripts lately for identifying letters in certain non-european languages that don't have uppercase or lowercase variants and wouldn't allow me to Proper Case the string (which I am doing in this script to all strings to which it can be done). – JohnRDOrazio Jan 10 '15 at 20:28
-
@Lwangaman Thanks for the reference and for fixing my jsfiddle! I incorporated your code to the script, and updated the answer. Initially I thought it was something more complex, but since it's just the union of the categories `Ll`, `Lu` and `Lt` then it's no big deal (though I'm still unsure whether this is just a Perl/XRegExp thing, or something that will make its way to the EcmaScript 6 standard - which hopefully will come soon and make my code obsolete... :P). – mgibsonbr Jan 10 '15 at 21:37
48
September 2018 (updated February 2019)
It seems that regexp /\p{L}/u for match letters (as unicode categories)
- works on Chrome 68.0.3440.106 and Safari 11.1.2 (13605.3.8)
- NOT working on Firefox 65.0 :(
Here is a working example
In below field you should be able to to type letters but not numbers<br>
<input type="text" name="field" onkeydown="return /\p{L}/u.test(event.key)" >I report this bug here.
Update
After over 2 years according to: 1500035 > 1361876 > 1634135 finally this bug is fixed and will be available in Firefox v.78+
Kamil Kiełczewski
- 85,173
- 29
- 368
- 345
33
[^\u0000-\u007F]+ for any characters which is not included ASCII characters.
For example:
function isNonLatinCharacters(s) {
return /[^\u0000-\u007F]/.test(s);
}
console.log(isNonLatinCharacters("身分"));// Japanese
console.log(isNonLatinCharacters("测试"));// Chinese
console.log(isNonLatinCharacters("حمید"));// Persian
console.log(isNonLatinCharacters("테스트"));// Korean
console.log(isNonLatinCharacters("परीक्षण"));// Hindi
console.log(isNonLatinCharacters("מִבְחָן"));// HebrewHere are some perfect references:
Unicode range RegExp generator
oguz ismail
- 1
- 16
- 47
- 69
Hamid Hoseini
- 1,560
- 17
- 21
32
As mentioned in other answers, JavaScript regexes have no support for Unicode character classes. However, there is a library that does provide this: Steven Levithan's excellent XRegExp and its Unicode plug-in.
Tim Down
- 318,141
- 75
- 454
- 536
-
4While this link may answer the question, it is better to include the essential parts of the answer here and provide the link for reference. Link-only answers can become invalid if the linked page changes. - [From Review](/review/low-quality-posts/12601405) – mustaccio Jun 06 '16 at 23:39
-
7@mustaccio: I disagree. This answer recommends the use of a library. If the library goes away then an answer that duplicates a snapshot of the library's documentation is as useless as one that just links to the library. – Tim Down Jun 07 '16 at 16:50
11
In JavaScript, \w and \d are ASCII, while \s is Unicode. Don't ask me why. JavaScript does support \p with Unicode categories, which you can use to emulate a Unicode-aware \w and \d.
For \d use \p{N} (numbers)
For \w use [\p{L}\p{N}\p{Pc}\p{M}] (letters, numbers, underscores, marks)
Update: Unfortunately, I was wrong about this. JavaScript does does not officially support \p either, though some implementations may still support this. The only Unicode support in JavaScript regexes is matching specific code points with \uFFFF. You can use those in ranges in character classes.
Jan Goyvaerts
- 21,379
- 7
- 60
- 72
-
30
-
2It is supported in Node 12. But one needs to add the u modifier: `/\p{L}+/u` – Ilya Semenov Oct 28 '19 at 08:01
-
I have been using `/[\p{L}\p{N}\p{Pc}\p{M}]/u.test(char)` and it works great. – Brian Schlenker Nov 08 '22 at 15:12
-
The `/u` flag did not exist when I wrote my answer in 2008. There was also a much greater difference between the JavaScript specification and the actual behavior of JavaScript and regexes in JavaScript at the time. – Jan Goyvaerts Nov 09 '22 at 05:42
10
This will do it:
/[A-Za-z\u00C0-\u00FF ]+/.exec('hipopótamo maçã pólen ñ poção água língüa')
It explicitly selects a range of unicode characters. It will work for latin characters, but other strange characters may be out of this range.
David Avsajanishvili
- 7,678
- 2
- 22
- 24
fiatjaf
- 11,479
- 5
- 56
- 72
-
This works nice. Why does it not work without a-z? Is that not in the same unicode range? – Jens Törnell Oct 26 '16 at 12:06
-
Note, that this does not cover full range of latin Unicode. There are more between `\u0100` and `\u0280`: many of those can be considered as latin characters but others not: var s = ''; for(var i=0xff; i<= 0x280; i++) { s += String.fromCharCode(i) } "ÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏ...ǐǑǒǓǔǕǖǗǘǙǚǛǜǝǞǟǠǡǢǣǤǥǦǧǨǩǪǫǬǭǮǯǰDZDzdzǴǵǶǷǸǹǺǻǼǽǾǿȀȁȂȃȄȅȆȇȈȉȊȋȌȍȎȏȐȑȒȓȔȕȖȗȘșȚțȜȝȞȟȠȡȢȣȤȥȦȧȨȩȪȫȬȭȮȯȰȱȲȳȴȵȶȷȸȹȺȻȼȽȾȿɀɁɂɃɄɅɆɇɈɉɊɋɌɍɎɏɐɑɒɓɔɕɖɗɘəɚɛɜɝɞɟɠɡɢɣɤɥɦɧɨɩɪɫɬɭɮɯɰɱɲɳɴɵɶɷɸɹɺɻɼɽɾɿʀ" – David Avsajanishvili Aug 24 '17 at 22:48
7
If you are using Babel then Unicode support is already available.
I also released a plugin which transforms your source code such that you can write regular expressions like /^\p{L}+$/. These will then be transformed into something that browsers understand.
Here is the project page of the plugin:
Peter Mortensen
- 30,738
- 21
- 105
- 131
Daniel
- 2,642
- 1
- 26
- 28
-
Note: the plugin [doesn't work with babel 6](https://github.com/danielberndt/babel-plugin-utf-8-regex/issues/1). – mik01aj Sep 07 '16 at 09:09
4
I'm answering this question
What would be the equivalent for \p{Lu} or \p{Ll} in regExp for js?
since it was marked as an exact duplicate of the current old question.
Querying the UCD Database of Unicode 12, \p{Lu} generates 1,788 code points.
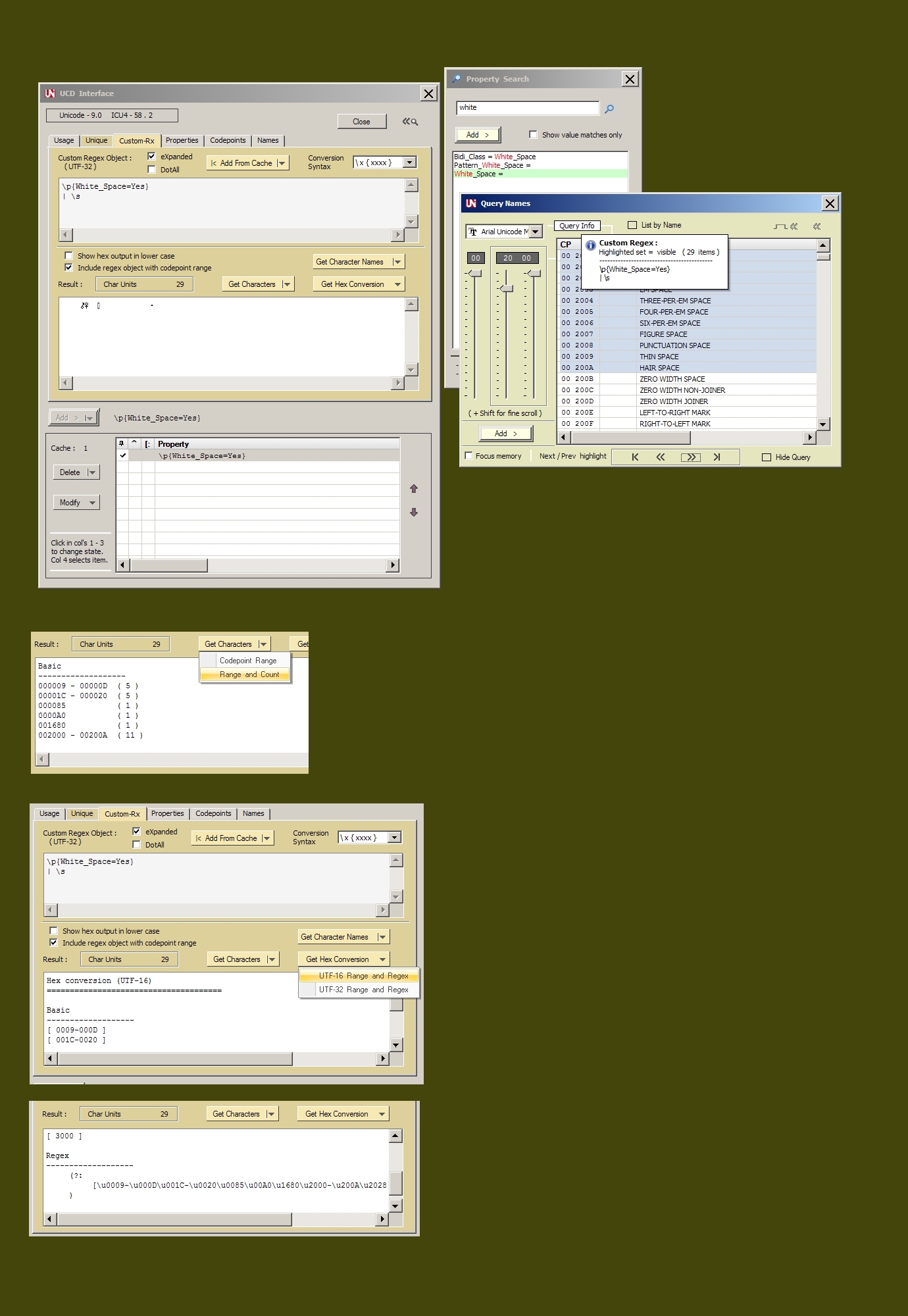{kind=link}
Converting to UTF-16 yields the class construct equivalency.
It's only a 4k character string and is easily doable in any regex engines.
(?:[\u0041-\u005A\u00C0-\u00D6\u00D8-\u00DE\u0100\u0102\u0104\u0106\u0108\u010A\u010C\u010E\u0110\u0112\u0114\u0116\u0118\u011A\u011C\u011E\u0120\u0122\u0124\u0126\u0128\u012A\u012C\u012E\u0130\u0132\u0134\u0136\u0139\u013B\u013D\u013F\u0141\u0143\u0145\u0147\u014A\u014C\u014E\u0150\u0152\u0154\u0156\u0158\u015A\u015C\u015E\u0160\u0162\u0164\u0166\u0168\u016A\u016C\u016E\u0170\u0172\u0174\u0176\u0178-\u0179\u017B\u017D\u0181-\u0182\u0184\u0186-\u0187\u0189-\u018B\u018E-\u0191\u0193-\u0194\u0196-\u0198\u019C-\u019D\u019F-\u01A0\u01A2\u01A4\u01A6-\u01A7\u01A9\u01AC\u01AE-\u01AF\u01B1-\u01B3\u01B5\u01B7-\u01B8\u01BC\u01C4\u01C7\u01CA\u01CD\u01CF\u01D1\u01D3\u01D5\u01D7\u01D9\u01DB\u01DE\u01E0\u01E2\u01E4\u01E6\u01E8\u01EA\u01EC\u01EE\u01F1\u01F4\u01F6-\u01F8\u01FA\u01FC\u01FE\u0200\u0202\u0204\u0206\u0208\u020A\u020C\u020E\u0210\u0212\u0214\u0216\u0218\u021A\u021C\u021E\u0220\u0222\u0224\u0226\u0228\u022A\u022C\u022E\u0230\u0232\u023A-\u023B\u023D-\u023E\u0241\u0243-\u0246\u0248\u024A\u024C\u024E\u0370\u0372\u0376\u037F\u0386\u0388-\u038A\u038C\u038E-\u038F\u0391-\u03A1\u03A3-\u03AB\u03CF\u03D2-\u03D4\u03D8\u03DA\u03DC\u03DE\u03E0\u03E2\u03E4\u03E6\u03E8\u03EA\u03EC\u03EE\u03F4\u03F7\u03F9-\u03FA\u03FD-\u042F\u0460\u0462\u0464\u0466\u0468\u046A\u046C\u046E\u0470\u0472\u0474\u0476\u0478\u047A\u047C\u047E\u0480\u048A\u048C\u048E\u0490\u0492\u0494\u0496\u0498\u049A\u049C\u049E\u04A0\u04A2\u04A4\u04A6\u04A8\u04AA\u04AC\u04AE\u04B0\u04B2\u04B4\u04B6\u04B8\u04BA\u04BC\u04BE\u04C0-\u04C1\u04C3\u04C5\u04C7\u04C9\u04CB\u04CD\u04D0\u04D2\u04D4\u04D6\u04D8\u04DA\u04DC\u04DE\u04E0\u04E2\u04E4\u04E6\u04E8\u04EA\u04EC\u04EE\u04F0\u04F2\u04F4\u04F6\u04F8\u04FA\u04FC\u04FE\u0500\u0502\u0504\u0506\u0508\u050A\u050C\u050E\u0510\u0512\u0514\u0516\u0518\u051A\u051C\u051E\u0520\u0522\u0524\u0526\u0528\u052A\u052C\u052E\u0531-\u0556\u10A0-\u10C5\u10C7\u10CD\u13A0-\u13F5\u1C90-\u1CBA\u1CBD-\u1CBF\u1E00\u1E02\u1E04\u1E06\u1E08\u1E0A\u1E0C\u1E0E\u1E10\u1E12\u1E14\u1E16\u1E18\u1E1A\u1E1C\u1E1E\u1E20\u1E22\u1E24\u1E26\u1E28\u1E2A\u1E2C\u1E2E\u1E30\u1E32\u1E34\u1E36\u1E38\u1E3A\u1E3C\u1E3E\u1E40\u1E42\u1E44\u1E46\u1E48\u1E4A\u1E4C\u1E4E\u1E50\u1E52\u1E54\u1E56\u1E58\u1E5A\u1E5C\u1E5E\u1E60\u1E62\u1E64\u1E66\u1E68\u1E6A\u1E6C\u1E6E\u1E70\u1E72\u1E74\u1E76\u1E78\u1E7A\u1E7C\u1E7E\u1E80\u1E82\u1E84\u1E86\u1E88\u1E8A\u1E8C\u1E8E\u1E90\u1E92\u1E94\u1E9E\u1EA0\u1EA2\u1EA4\u1EA6\u1EA8\u1EAA\u1EAC\u1EAE\u1EB0\u1EB2\u1EB4\u1EB6\u1EB8\u1EBA\u1EBC\u1EBE\u1EC0\u1EC2\u1EC4\u1EC6\u1EC8\u1ECA\u1ECC\u1ECE\u1ED0\u1ED2\u1ED4\u1ED6\u1ED8\u1EDA\u1EDC\u1EDE\u1EE0\u1EE2\u1EE4\u1EE6\u1EE8\u1EEA\u1EEC\u1EEE\u1EF0\u1EF2\u1EF4\u1EF6\u1EF8\u1EFA\u1EFC\u1EFE\u1F08-\u1F0F\u1F18-\u1F1D\u1F28-\u1F2F\u1F38-\u1F3F\u1F48-\u1F4D\u1F59\u1F5B\u1F5D\u1F5F\u1F68-\u1F6F\u1FB8-\u1FBB\u1FC8-\u1FCB\u1FD8-\u1FDB\u1FE8-\u1FEC\u1FF8-\u1FFB\u2102\u2107\u210B-\u210D\u2110-\u2112\u2115\u2119-\u211D\u2124\u2126\u2128\u212A-\u212D\u2130-\u2133\u213E-\u213F\u2145\u2183\u2C00-\u2C2E\u2C60\u2C62-\u2C64\u2C67\u2C69\u2C6B\u2C6D-\u2C70\u2C72\u2C75\u2C7E-\u2C80\u2C82\u2C84\u2C86\u2C88\u2C8A\u2C8C\u2C8E\u2C90\u2C92\u2C94\u2C96\u2C98\u2C9A\u2C9C\u2C9E\u2CA0\u2CA2\u2CA4\u2CA6\u2CA8\u2CAA\u2CAC\u2CAE\u2CB0\u2CB2\u2CB4\u2CB6\u2CB8\u2CBA\u2CBC\u2CBE\u2CC0\u2CC2\u2CC4\u2CC6\u2CC8\u2CCA\u2CCC\u2CCE\u2CD0\u2CD2\u2CD4\u2CD6\u2CD8\u2CDA\u2CDC\u2CDE\u2CE0\u2CE2\u2CEB\u2CED\u2CF2\uA640\uA642\uA644\uA646\uA648\uA64A\uA64C\uA64E\uA650\uA652\uA654\uA656\uA658\uA65A\uA65C\uA65E\uA660\uA662\uA664\uA666\uA668\uA66A\uA66C\uA680\uA682\uA684\uA686\uA688\uA68A\uA68C\uA68E\uA690\uA692\uA694\uA696\uA698\uA69A\uA722\uA724\uA726\uA728\uA72A\uA72C\uA72E\uA732\uA734\uA736\uA738\uA73A\uA73C\uA73E\uA740\uA742\uA744\uA746\uA748\uA74A\uA74C\uA74E\uA750\uA752\uA754\uA756\uA758\uA75A\uA75C\uA75E\uA760\uA762\uA764\uA766\uA768\uA76A\uA76C\uA76E\uA779\uA77B\uA77D-\uA77E\uA780\uA782\uA784\uA786\uA78B\uA78D\uA790\uA792\uA796\uA798\uA79A\uA79C\uA79E\uA7A0\uA7A2\uA7A4\uA7A6\uA7A8\uA7AA-\uA7AE\uA7B0-\uA7B4\uA7B6\uA7B8\uA7BA\uA7BC\uA7BE\uA7C2\uA7C4-\uA7C6\uFF21-\uFF3A]|(?:\uD801[\uDC00-\uDC27\uDCB0-\uDCD3]|\uD803[\uDC80-\uDCB2]|\uD806[\uDCA0-\uDCBF]|\uD81B[\uDE40-\uDE5F]|\uD835[\uDC00-\uDC19\uDC34-\uDC4D\uDC68-\uDC81\uDC9C\uDC9E-\uDC9F\uDCA2\uDCA5-\uDCA6\uDCA9-\uDCAC\uDCAE-\uDCB5\uDCD0-\uDCE9\uDD04-\uDD05\uDD07-\uDD0A\uDD0D-\uDD14\uDD16-\uDD1C\uDD38-\uDD39\uDD3B-\uDD3E\uDD40-\uDD44\uDD46\uDD4A-\uDD50\uDD6C-\uDD85\uDDA0-\uDDB9\uDDD4-\uDDED\uDE08-\uDE21\uDE3C-\uDE55\uDE70-\uDE89\uDEA8-\uDEC0\uDEE2-\uDEFA\uDF1C-\uDF34\uDF56-\uDF6E\uDF90-\uDFA8\uDFCA]|\uD83A[\uDD00-\uDD21]))
Querying the UCD database of Unicode 12, \p{Ll} generates 2,151 code points.
Converting to UTF-16 yields the class construct equivalency.
(?:[\u0061-\u007A\u00B5\u00DF-\u00F6\u00F8-\u00FF\u0101\u0103\u0105\u0107\u0109\u010B\u010D\u010F\u0111\u0113\u0115\u0117\u0119\u011B\u011D\u011F\u0121\u0123\u0125\u0127\u0129\u012B\u012D\u012F\u0131\u0133\u0135\u0137-\u0138\u013A\u013C\u013E\u0140\u0142\u0144\u0146\u0148-\u0149\u014B\u014D\u014F\u0151\u0153\u0155\u0157\u0159\u015B\u015D\u015F\u0161\u0163\u0165\u0167\u0169\u016B\u016D\u016F\u0171\u0173\u0175\u0177\u017A\u017C\u017E-\u0180\u0183\u0185\u0188\u018C-\u018D\u0192\u0195\u0199-\u019B\u019E\u01A1\u01A3\u01A5\u01A8\u01AA-\u01AB\u01AD\u01B0\u01B4\u01B6\u01B9-\u01BA\u01BD-\u01BF\u01C6\u01C9\u01CC\u01CE\u01D0\u01D2\u01D4\u01D6\u01D8\u01DA\u01DC-\u01DD\u01DF\u01E1\u01E3\u01E5\u01E7\u01E9\u01EB\u01ED\u01EF-\u01F0\u01F3\u01F5\u01F9\u01FB\u01FD\u01FF\u0201\u0203\u0205\u0207\u0209\u020B\u020D\u020F\u0211\u0213\u0215\u0217\u0219\u021B\u021D\u021F\u0221\u0223\u0225\u0227\u0229\u022B\u022D\u022F\u0231\u0233-\u0239\u023C\u023F-\u0240\u0242\u0247\u0249\u024B\u024D\u024F-\u0293\u0295-\u02AF\u0371\u0373\u0377\u037B-\u037D\u0390\u03AC-\u03CE\u03D0-\u03D1\u03D5-\u03D7\u03D9\u03DB\u03DD\u03DF\u03E1\u03E3\u03E5\u03E7\u03E9\u03EB\u03ED\u03EF-\u03F3\u03F5\u03F8\u03FB-\u03FC\u0430-\u045F\u0461\u0463\u0465\u0467\u0469\u046B\u046D\u046F\u0471\u0473\u0475\u0477\u0479\u047B\u047D\u047F\u0481\u048B\u048D\u048F\u0491\u0493\u0495\u0497\u0499\u049B\u049D\u049F\u04A1\u04A3\u04A5\u04A7\u04A9\u04AB\u04AD\u04AF\u04B1\u04B3\u04B5\u04B7\u04B9\u04BB\u04BD\u04BF\u04C2\u04C4\u04C6\u04C8\u04CA\u04CC\u04CE-\u04CF\u04D1\u04D3\u04D5\u04D7\u04D9\u04DB\u04DD\u04DF\u04E1\u04E3\u04E5\u04E7\u04E9\u04EB\u04ED\u04EF\u04F1\u04F3\u04F5\u04F7\u04F9\u04FB\u04FD\u04FF\u0501\u0503\u0505\u0507\u0509\u050B\u050D\u050F\u0511\u0513\u0515\u0517\u0519\u051B\u051D\u051F\u0521\u0523\u0525\u0527\u0529\u052B\u052D\u052F\u0560-\u0588\u10D0-\u10FA\u10FD-\u10FF\u13F8-\u13FD\u1C80-\u1C88\u1D00-\u1D2B\u1D6B-\u1D77\u1D79-\u1D9A\u1E01\u1E03\u1E05\u1E07\u1E09\u1E0B\u1E0D\u1E0F\u1E11\u1E13\u1E15\u1E17\u1E19\u1E1B\u1E1D\u1E1F\u1E21\u1E23\u1E25\u1E27\u1E29\u1E2B\u1E2D\u1E2F\u1E31\u1E33\u1E35\u1E37\u1E39\u1E3B\u1E3D\u1E3F\u1E41\u1E43\u1E45\u1E47\u1E49\u1E4B\u1E4D\u1E4F\u1E51\u1E53\u1E55\u1E57\u1E59\u1E5B\u1E5D\u1E5F\u1E61\u1E63\u1E65\u1E67\u1E69\u1E6B\u1E6D\u1E6F\u1E71\u1E73\u1E75\u1E77\u1E79\u1E7B\u1E7D\u1E7F\u1E81\u1E83\u1E85\u1E87\u1E89\u1E8B\u1E8D\u1E8F\u1E91\u1E93\u1E95-\u1E9D\u1E9F\u1EA1\u1EA3\u1EA5\u1EA7\u1EA9\u1EAB\u1EAD\u1EAF\u1EB1\u1EB3\u1EB5\u1EB7\u1EB9\u1EBB\u1EBD\u1EBF\u1EC1\u1EC3\u1EC5\u1EC7\u1EC9\u1ECB\u1ECD\u1ECF\u1ED1\u1ED3\u1ED5\u1ED7\u1ED9\u1EDB\u1EDD\u1EDF\u1EE1\u1EE3\u1EE5\u1EE7\u1EE9\u1EEB\u1EED\u1EEF\u1EF1\u1EF3\u1EF5\u1EF7\u1EF9\u1EFB\u1EFD\u1EFF-\u1F07\u1F10-\u1F15\u1F20-\u1F27\u1F30-\u1F37\u1F40-\u1F45\u1F50-\u1F57\u1F60-\u1F67\u1F70-\u1F7D\u1F80-\u1F87\u1F90-\u1F97\u1FA0-\u1FA7\u1FB0-\u1FB4\u1FB6-\u1FB7\u1FBE\u1FC2-\u1FC4\u1FC6-\u1FC7\u1FD0-\u1FD3\u1FD6-\u1FD7\u1FE0-\u1FE7\u1FF2-\u1FF4\u1FF6-\u1FF7\u210A\u210E-\u210F\u2113\u212F\u2134\u2139\u213C-\u213D\u2146-\u2149\u214E\u2184\u2C30-\u2C5E\u2C61\u2C65-\u2C66\u2C68\u2C6A\u2C6C\u2C71\u2C73-\u2C74\u2C76-\u2C7B\u2C81\u2C83\u2C85\u2C87\u2C89\u2C8B\u2C8D\u2C8F\u2C91\u2C93\u2C95\u2C97\u2C99\u2C9B\u2C9D\u2C9F\u2CA1\u2CA3\u2CA5\u2CA7\u2CA9\u2CAB\u2CAD\u2CAF\u2CB1\u2CB3\u2CB5\u2CB7\u2CB9\u2CBB\u2CBD\u2CBF\u2CC1\u2CC3\u2CC5\u2CC7\u2CC9\u2CCB\u2CCD\u2CCF\u2CD1\u2CD3\u2CD5\u2CD7\u2CD9\u2CDB\u2CDD\u2CDF\u2CE1\u2CE3-\u2CE4\u2CEC\u2CEE\u2CF3\u2D00-\u2D25\u2D27\u2D2D\uA641\uA643\uA645\uA647\uA649\uA64B\uA64D\uA64F\uA651\uA653\uA655\uA657\uA659\uA65B\uA65D\uA65F\uA661\uA663\uA665\uA667\uA669\uA66B\uA66D\uA681\uA683\uA685\uA687\uA689\uA68B\uA68D\uA68F\uA691\uA693\uA695\uA697\uA699\uA69B\uA723\uA725\uA727\uA729\uA72B\uA72D\uA72F-\uA731\uA733\uA735\uA737\uA739\uA73B\uA73D\uA73F\uA741\uA743\uA745\uA747\uA749\uA74B\uA74D\uA74F\uA751\uA753\uA755\uA757\uA759\uA75B\uA75D\uA75F\uA761\uA763\uA765\uA767\uA769\uA76B\uA76D\uA76F\uA771-\uA778\uA77A\uA77C\uA77F\uA781\uA783\uA785\uA787\uA78C\uA78E\uA791\uA793-\uA795\uA797\uA799\uA79B\uA79D\uA79F\uA7A1\uA7A3\uA7A5\uA7A7\uA7A9\uA7AF\uA7B5\uA7B7\uA7B9\uA7BB\uA7BD\uA7BF\uA7C3\uA7FA\uAB30-\uAB5A\uAB60-\uAB67\uAB70-\uABBF\uFB00-\uFB06\uFB13-\uFB17\uFF41-\uFF5A]|(?:\uD801[\uDC28-\uDC4F\uDCD8-\uDCFB]|\uD803[\uDCC0-\uDCF2]|\uD806[\uDCC0-\uDCDF]|\uD81B[\uDE60-\uDE7F]|\uD835[\uDC1A-\uDC33\uDC4E-\uDC54\uDC56-\uDC67\uDC82-\uDC9B\uDCB6-\uDCB9\uDCBB\uDCBD-\uDCC3\uDCC5-\uDCCF\uDCEA-\uDD03\uDD1E-\uDD37\uDD52-\uDD6B\uDD86-\uDD9F\uDDBA-\uDDD3\uDDEE-\uDE07\uDE22-\uDE3B\uDE56-\uDE6F\uDE8A-\uDEA5\uDEC2-\uDEDA\uDEDC-\uDEE1\uDEFC-\uDF14\uDF16-\uDF1B\uDF36-\uDF4E\uDF50-\uDF55\uDF70-\uDF88\uDF8A-\uDF8F\uDFAA-\uDFC2\uDFC4-\uDFC9\uDFCB]|\uD83A[\uDD22-\uDD43]))
Note that a regex implementation of \p{Lu} or \p{Pl} actually calls a
non standard function to test the value.
The character classes shown here are done differently and are linear, standard
and pretty slow, when jammed into mostly a single class.
Some insight on how a Regex engine (in general) implements Unicode Property Classes:
Examine these performance characteristics between the property
and the class block (like above)
Regex1: LONG CLASS
< none >
Completed iterations: 50 / 50 ( x 1 )
Matches found per iteration: 1788
Elapsed Time: 0.73 s, 727.58 ms, 727584 µs
Matches per sec: 122,872
Regex2: \p{Lu}
Options: < ICU - none >
Completed iterations: 50 / 50 ( x 1 )
Matches found per iteration: 1788
Elapsed Time: 0.07 s, 65.32 ms, 65323 µs
Matches per sec: 1,368,583
Wow what a difference !!
Lets see how Properties might be implemented
Array of Pointers [ 10FFFF ] where each index is is a Code Point
Each pointer in the Array is to a structure of classification.
A Classification structure contains fixed field elemets.
Some are NULL and do not pertain.
Some contain category classifications.Example : General Category
This is a bitmapped element that uses 17 out of 64 bits.
Whatever this Code Point supports has bit(s) set as a mask.-Close_Punctuation
-Connector_Punctuation
-Control
-Currency_Symbol
-Dash_Punctuation
-Decimal_Number
-Enclosing_Mark
-Final_Punctuation
-Format
-Initial_Punctuation
-Letter_Number
-Line_Separator
-Lowercase_Letter
-Math_Symbol
-Modifier_Letter
-Modifier_Symbol
-Nonspacing_Mark
-Open_Punctuation
-Other_Letter
-Other_Number
-Other_Punctuation
-Other_Symbol
-Paragraph_Separator
-Private_Use
-Space_Separator
-Spacing_Mark
-Surrogate
-Titlecase_Letter
-Unassigned
-Uppercase_Letter
When a regex is parsed with something like this \p{Lu} it
is translated directly into
- Classification Structure element offset : General Category
- A check of that element for bit item : Uppercase_Letter
Another example, when a regex is parsed with punctuation property \p{P} it
is translated into
- Classification Structure element offset : General Category
A check of that element for any of these items bits, which are joined into a mask :
-Close_Punctuation
-Connector_Punctuation
-Dash_Punctuation
-Final_Punctuation
-Initial_Punctuation
-Open_Punctuation
-Other_Punctuation
The offset and bit or bit(mask) are stored as a regex step for that property.
The lookup table is created once for all Unicode Code Points using this array.
When a character is checked, it is as simple as using the CP as an index into this array and checking the Classification Structure's specific element for that bit(mask).
This structure is expandable and indirect to provide much more complex look ups. This is just a simple example.
Compare that direct lookup with a character class search :
All classes are a linear list of items searched from left to right.
In this comparison, given our target string contains only the complete
Upper Case Unicode Letters only, the law of averages would predict that
half of the items in the class would have to be ranged checked
to find a match.
This is a huge disadvantage in performance.
However, if the lookup tables are not there or are not up to date
with the latest Unicode release (12 as of this date)
then this would be the only way.
In fact, it is mostly the only way to get the complete Emoji
characters as there is no specific property (or reasoning) to their assignment.
-
Its quite frustrating one has to go through all this to do something other languages made so simple. – nicolasassi Nov 22 '19 at 18:31
-
1@nicolasassi - It's not really as straight forward as it looks. Unicode tables (and property's) would seem hard to maintain given the wide distribution of engines and the rapidly changing Standard itself. Added some more insight in the post. – Nov 22 '19 at 22:43
3
You can also use:
function myFunction() {
var str = "xq234";
var allowChars = "^[a-zA-ZÀ-ÿ]+$";
var res = str.match(allowChars);
if(!str.match(allowChars)){
res="true";
}
else {
res="false";
}
document.getElementById("demo").innerHTML = res;
Alex Myers
- 6,196
- 7
- 23
- 39
Tapan Upadhyay
- 81
- 1
- 6