The 'way it's done' is to use homogenous transformations and coordinates. You take a point in space and:
- Position it relative to the camera using the model matrix.
- Project it either orthographically or in perspective using the projection matrix.
- Apply the viewport trnasformation to place it on the screen.
This gets pretty vague, but I'll try and cover the important bits and leave some of it to you. I assume you understand the basics of matrix math :).
Homogenous Vectors, Points, Transformations
In 3D, a homogenous point would be a column matrix of the form [x, y, z, 1]. The final component is 'w', a scaling factor, which for vectors is 0: this has the effect that you can't translate vectors, which is mathematically correct. We won't go there, we're talking points.
Homogenous transformations are 4x4 matrices, used because they allow translation to be represented as a matrix multiplication, rather than an addition, which is nice and quick for your videocard. Also convenient because we can represent successive transformations by multiplying them together. We apply transformations to points by performing transformation * point.
There are 3 primary homogeneous transformations:
There are others, notably the 'look at' transformation, which are worth exploring. However, I just wanted to give a brief list and a few links. Successive application of moving, scaling and rotating applied to points is collectively the model transformation matrix, and places them in the scene, relative to the camera. It's important to realise what we're doing is akin to moving objects around the camera, not the other way around.
Orthographic and Perspective
To transform from world coordinates into screen coordinates, you would first use a projection matrix, which commonly, come in two flavors:
- Orthographic, commonly used for 2D and CAD.
- Perspective, good for games and 3D environments.
An orthographic projection matrix is constructed as follows:

Where parameters include:
- Top: The Y coordinate of the top edge of visible space.
- Bottom: The Y coordinate of the bottom edge of the visible space.
- Left: The X coordinate of the left edge of the visible space.
- Right: The X coordinate of the right edge of the visible space.
I think that's pretty simple. What you establish is an area of space that is going to appear on the screen, which you can clip against. It's simple here, because the area of space visible is a rectangle. Clipping in perspective is more complicated because the area which appears on screen or the viewing volume, is a frustrum.
If you're having a hard time with the wikipedia on perspective projection, Here's the code to build a suitable matrix, courtesy of geeks3D
void BuildPerspProjMat(float *m, float fov, float aspect,
float znear, float zfar)
{
float xymax = znear * tan(fov * PI_OVER_360);
float ymin = -xymax;
float xmin = -xymax;
float width = xymax - xmin;
float height = xymax - ymin;
float depth = zfar - znear;
float q = -(zfar + znear) / depth;
float qn = -2 * (zfar * znear) / depth;
float w = 2 * znear / width;
w = w / aspect;
float h = 2 * znear / height;
m[0] = w;
m[1] = 0;
m[2] = 0;
m[3] = 0;
m[4] = 0;
m[5] = h;
m[6] = 0;
m[7] = 0;
m[8] = 0;
m[9] = 0;
m[10] = q;
m[11] = -1;
m[12] = 0;
m[13] = 0;
m[14] = qn;
m[15] = 0;
}
Variables are:
- fov: Field of view, pi/4 radians is a good value.
- aspect: Ratio of height to width.
- znear, zfar: used for clipping, I'll ignore these.
and the matrix generated is column major, indexed as follows in the above code:
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
Viewport Transformation, Screen Coordinates
Both of these transformations require another matrix matrix to put things in screen coordinates, called the viewport transformation. That's described here, I won't cover it (it's dead simple).
Thus, for a point p, we would:
- Perform model transformation matrix * p, resulting in pm.
- Perform projection matrix * pm, resulting in pp.
- Clipping pp against the viewing volume.
- Perform viewport transformation matrix * pp, resulting is ps: point on screen.
Summary
I hope that covers most of it. There are holes in the above and it's vague in places, post any questions below. This subject is usually worthy of a whole chapter in a textbook, I've done my best to distill the process, hopefully to your advantage!
I linked to this above, but I strongly suggest you read this, and download the binary. It's an excellent tool to further your understanding of theses transformations and how it gets points on the screen:
http://www.songho.ca/opengl/gl_transform.html
As far as actual work, you'll need to implement a 4x4 matrix class for homogeneous transformations as well as a homogeneous point class you can multiply against it to apply transformations (remember, [x, y, z, 1]). You'll need to generate the transformations as described above and in the links. It's not all that difficult once you understand the procedure. Best of luck :).


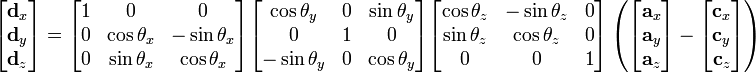{kind=link}
{kind=link}
{kind=link}