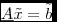I have a MySQL-table (MyISAM) containing about 200k entries of lat/long pairs that I select from, based on the pairs distance (great circle formula) from another lat/long pair. (e.g. all entries that are within a 10km radius around 50.281852, 2.504883)
My problem is that this query takes about 0,28 sec. to run just for those 200k entries (which continue to get more every day). While 0,28 sec. would be fine normally, this query runs very often as it powers the main feature of my web-app, and often times it's part of a larger query.
Is there any way to speed this up? Obviously MySQL has to run through all 200k entries every time and perform the great circle formula for every entry. I read something about geohashing, R-Trees and the like here on Stack Overflow but I don't think that's the way I want to go. Partly because I've never been a big fan of maths, but mostly because I think that this problem has already been solved by someone smarter than me in a library/extension/etc. that has been tested extensively and is being updated regularly.
MySQL seems to have a spatial extension but that one doesn't provide a distance function. Should I be looking at another database to put this coordinate-pairs in? PostgreSQL seems to have a fairly mature Spatial extension. Do you know anything about it? Or would PostgreSQL too simply just use the great circle formula to get all entries within a certain region?
Is there maybe a specialized stand-alone product or mysql-extension that already does what I'm looking for?
Or is there maybe A PHP library I could use to do the calculations? Using APC I could easily fit the lat-long pairs into memory (those 200k entries take about 5MB) and then run the query inside of PHP. The problem with this approach however is that then I'd have a MySQL query like SELECT .. FROM .. WHERE id in (id1, id2, ..) for all the results which can be up to a few thousand. How well does MySQL handle Queries like these? And then (since this is a number-crunching task) would doing this in PHP be fast enough?
Any other Ideas what I should/shouldn't do?
For completeness, here is the sample query, stripped of any irrelevant parts (as I said, usually this is part of a bigger query where I join multiple tables):
SELECT id,
6371 * acos( sin( radians( 52.4042924 ) ) * sin( radians( lat ) ) + cos( radians( 50.281852 ) ) * cos( radians( lat ) ) * cos( radians( 2.504883 ) - radians( lon ) ) ) AS dst
FROM geoloc
HAVING dst <10
ORDER BY dst ASC