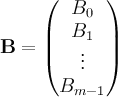I'd like to generate matrices of size mxn and rank r, with elements coming from a specified finite set, e.g. {0,1} or {1,2,3,4,5}. I want them to be "random" in some very loose sense of that word, i.e. I want to get a variety of possible outputs from the algorithm with distribution vaguely similar to the distribution of all matrices over that set of elements with the specified rank.
In fact, I don't actually care that it has rank r, just that it's close to a matrix of rank r (measured by the Frobenius norm).
When the set at hand is the reals, I've been doing the following, which is perfectly adequate for my needs: generate matrices U of size mxr and V of nxr, with elements independently sampled from e.g. Normal(0, 2). Then U V' is an mxn matrix of rank r (well, <= r, but I think it's r with high probability).
If I just do that and then round to binary / 1-5, though, the rank increases.
It's also possible to get a lower-rank approximation to a matrix by doing an SVD and taking the first r singular values. Those values, though, won't lie in the desired set, and rounding them will again increase the rank.
This question is related, but accepted answer isn't "random," and the other answer suggests SVD, which doesn't work here as noted.
One possibility I've thought of is to make r linearly independent row or column vectors from the set and then get the rest of the matrix by linear combinations of those. I'm not really clear, though, either on how to get "random" linearly independent vectors, or how to combine them in a quasirandom way after that.
(Not that it's super-relevant, but I'm doing this in numpy.)
Update: I've tried the approach suggested by EMS in the comments, with this simple implementation:
real = np.dot(np.random.normal(0, 1, (10, 3)), np.random.normal(0, 1, (3, 10)))
bin = (real > .5).astype(int)
rank = np.linalg.matrix_rank(bin)
niter = 0
while rank > des_rank:
cand_changes = np.zeros((21, 5))
for n in range(20):
i, j = random.randrange(5), random.randrange(5)
v = 1 - bin[i,j]
x = bin.copy()
x[i, j] = v
x_rank = np.linalg.matrix_rank(x)
cand_changes[n,:] = (i, j, v, x_rank, max((rank + 1e-4) - x_rank, 0))
cand_changes[-1,:] = (0, 0, bin[0,0], rank, 1e-4)
cdf = np.cumsum(cand_changes[:,-1])
cdf /= cdf[-1]
i, j, v, rank, score = cand_changes[np.searchsorted(cdf, random.random()), :]
bin[i, j] = v
niter += 1
if niter % 1000 == 0:
print(niter, rank)
It works quickly for small matrices but falls apart for e.g. 10x10 -- it seems to get stuck at rank 6 or 7, at least for hundreds of thousands of iterations.
It seems like this might work better with a better (ie less-flat) objective function, but I don't know what that would be.
I've also tried a simple rejection method for building up the matrix:
def fill_matrix(m, n, r, vals):
assert m >= r and n >= r
trans = False
if m > n: # more columns than rows I think is better
m, n = n, m
trans = True
get_vec = lambda: np.array([random.choice(vals) for i in range(n)])
vecs = []
n_rejects = 0
# fill in r linearly independent rows
while len(vecs) < r:
v = get_vec()
if np.linalg.matrix_rank(np.vstack(vecs + [v])) > len(vecs):
vecs.append(v)
else:
n_rejects += 1
print("have {} independent ({} rejects)".format(r, n_rejects))
# fill in the rest of the dependent rows
while len(vecs) < m:
v = get_vec()
if np.linalg.matrix_rank(np.vstack(vecs + [v])) > len(vecs):
n_rejects += 1
if n_rejects % 1000 == 0:
print(n_rejects)
else:
vecs.append(v)
print("done ({} total rejects)".format(n_rejects))
m = np.vstack(vecs)
return m.T if trans else m
This works okay for e.g. 10x10 binary matrices with any rank, but not for 0-4 matrices or much larger binaries with lower rank. (For example, getting a 20x20 binary matrix of rank 15 took me 42,000 rejections; with 20x20 of rank 10, it took 1.2 million.)
This is clearly because the space spanned by the first r rows is too small a portion of the space I'm sampling from, e.g. {0,1}^10, in these cases.
We want the intersection of the span of the first r rows with the set of valid values.
So we could try sampling from the span and looking for valid values, but since the span involves real-valued coefficients that's never going to find us valid vectors (even if we normalize so that e.g. the first component is in the valid set).
Maybe this can be formulated as an integer programming problem, or something?