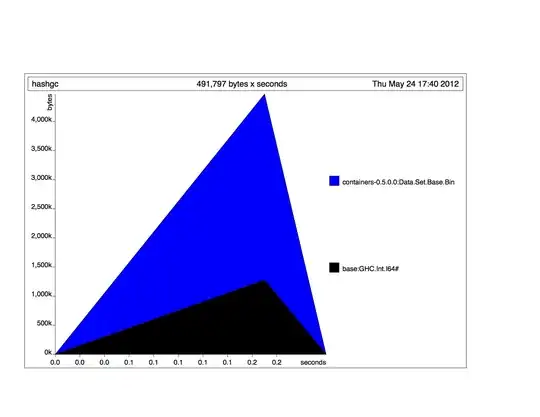
This program creates a very large set to find a hash function collision. Is there a way to reduce the amount of time spent in GC? +RTS -s is reporting 40+% time spent in GC.
Example usage:
./program 0 1000000 +RTS -s
./program 145168473 10200000 +RTS -s
Is there a better algorithm or data structure I can use?
{-# LANGUAGE OverloadedStrings #-}
import System.Environment
import Control.Monad
import Crypto.Hash.SHA256
import qualified Data.ByteString.Char8 as B
import qualified Data.ByteString.Lazy.Char8 as BL
import Data.Char
import Data.Int
import Data.Bits
import Data.Binary
import Data.Set as Set
import Data.List
import Numeric
str2int :: (Integral a) => B.ByteString -> a
str2int bs = B.foldl (\a w -> (a * 256)+(fromIntegral $ ord w)) 0 bs
t50 :: Int64 -> Int64
t50 i = let h = hash $ B.concat $ BL.toChunks $ encode i
in
(str2int $ B.drop 25 h) .&. 0x3ffffffffffff
sha256 :: Int64 -> B.ByteString
sha256 i = hash $ B.concat $ BL.toChunks $ encode i
-- firstCollision :: Ord b => (a -> b) -> [a] -> Maybe a
firstCollision f xs = go f Set.empty xs
where
-- go :: Ord b => (a -> b) -> Set b -> [a] -> Maybe a
go _ _ [] = Nothing
go f s (x:xs) = let y = f x
in
if y `Set.member` s
then Just x
else go f (Set.insert y s) xs
showHex2 i
| i < 16 = "0" ++ (showHex i "")
| otherwise = showHex i ""
prettyPrint :: B.ByteString -> String
prettyPrint = concat . (Data.List.map showHex2) . (Data.List.map ord) . B.unpack
showhash inp =
let h = sha256 inp
x = B.concat $ BL.toChunks $ encode inp
in do putStrLn $ " - input: " ++ (prettyPrint x) ++ " -- " ++ (show inp)
putStrLn $ " - hash: " ++ (prettyPrint h)
main = do
args <- getArgs
let a = (read $ args !! 0) :: Int64
b = (read $ args !! 1) :: Int64
c = firstCollision t [a..(a+b)]
t = t50
case c of
Nothing -> putStrLn "No collision found"
Just x -> do let h = t x
putStrLn $ "Found collision at " ++ (show x)
showhash x
let first = find (\x -> (t x) == h) [a..(a+b)]
in case first of
Nothing -> putStrLn "oops -- failed to find hash"
Just x0 -> do putStrLn $ "first instance at " ++ (show x0)
showhash x0