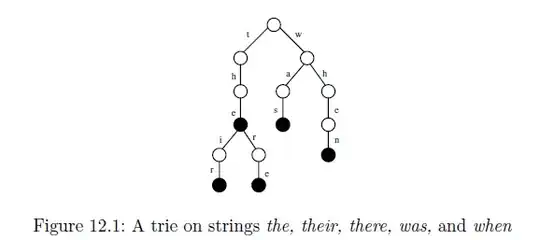
I'm not able to understand how that tree gets generated from the given input string.
You essentially create a patricia trie with all the suffixes you've listed. When inserting into a patricia trie, you search the root for a child starting with the first char from the input string, if it exists you continue down the tree but if it doesn't then you create a new node off the root. The root will have as many children as unique characters in the input string ($, a, e, h, i, n, r, s, t, w). You can continue that process for each character in the input string.
Suffix trees are used to find a given Substring in a given String, but how does the given tree help towards that?
If you are looking for substring "hen" then start searching from the root for a child which starts with "h". If the length of the string of in child "h" then continue to process child "h" until you've come to the end of the string or you get a mismatch of characters in input string and child "h" string. If you match all of child "h", i.e. input "hen" matches "he" in child "h" then move on to the children of "h" until you get to "n", if it fail to find a child beginning with "n" then the substring doesn't exist.
Compact Suffix Trie code:
└── (black)
├── (white) as
├── (white) e
│ ├── (white) eir
│ ├── (white) en
│ └── (white) ere
├── (white) he
│ ├── (white) heir
│ ├── (white) hen
│ └── (white) here
├── (white) ir
├── (white) n
├── (white) r
│ └── (white) re
├── (white) s
├── (white) the
│ ├── (white) their
│ └── (white) there
└── (black) w
├── (white) was
└── (white) when
Suffix Tree code:
String = the$their$there$was$when$
End of word character = $
└── (0)
├── (22) $
├── (25) as$
├── (9) e
│ ├── (10) ir$
│ ├── (32) n$
│ └── (17) re$
├── (7) he
│ ├── (2) $
│ ├── (8) ir$
│ ├── (31) n$
│ └── (16) re$
├── (11) ir$
├── (33) n$
├── (18) r
│ ├── (12) $
│ └── (19) e$
├── (26) s$
├── (5) the
│ ├── (1) $
│ ├── (6) ir$
│ └── (15) re$
└── (29) w
├── (24) as$
└── (30) hen$