UPDATE: I found a solution. See my Answer below.
My Question
How can I optimize this query to minimize my downtime? I need to update over 50 schemas with the number of tickets ranging from 100,000 to 2 million. Is it advisable to attempt to set all fields in tickets_extra at the same time? I feel that there is a solution here that I'm just not seeing. Ive been banging my head against this problem for over a day.
Also, I initially tried without using a sub SELECT, but the performance was much worse than what I currently have.
Background
I'm trying to optimize my database for a report that needs to be run. The fields I need to aggregate on are very expensive to calculate, so I am denormalizing my existing schema a bit to accommodate this report. Note that I simplified the tickets table quite a bit by removing a few dozen irrelevant columns.
My report will be aggregating ticket counts by Manager When Created and Manager When Resolved. This complicated relationship is diagrammed here:

(source: mosso.com)
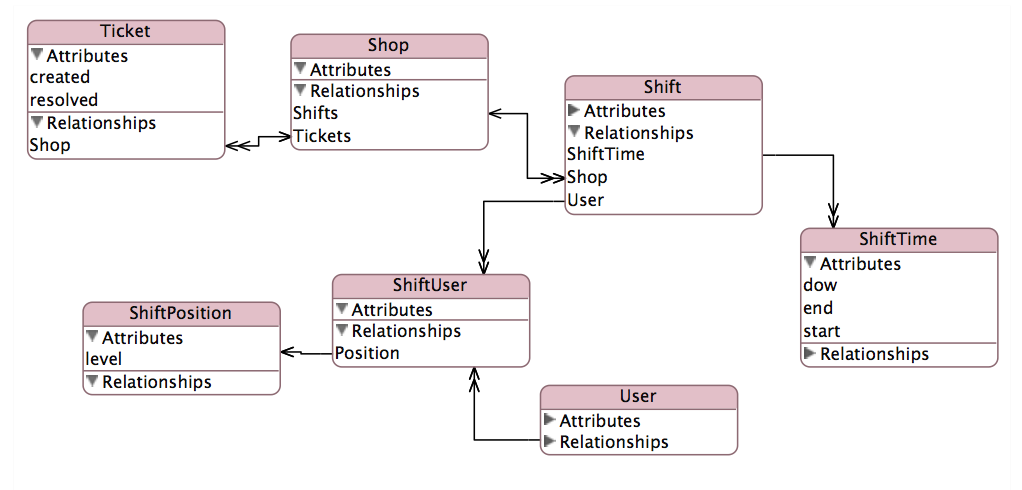{kind=link}
To avoid the half dozen nasty joins required to calculate this on-the-fly I've added the following table to my schema:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
The problem now is, I haven't been storing this data anywhere. The manager was always calculated dynamically. I have millions of tickets across several databases with the same schema that need to have this table populated. I want to do this in as efficient a way as possible, but have been unsuccessful in optimizing the queries I'm using to do so:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
This query takes over an hour to run on a schema that has > 1.7 million tickets. This is unacceptable for the maintenance window I have. Also, it doesn't even handle calculating the manager_resolved field, as attempting to combine that into the same query pushes the query time into the stratosphere. My current inclination is to keep them separate, and use an UPDATE to populate the manager_resolved field, but I'm not sure.
Finally, here is the EXPLAIN output of the SELECT portion of that query:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Thank you so much for reading!