Note that release/acquire semantics do not necessarily imply a mfence after each instruction. On x86 holds 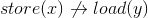 as can be seen in the manual referenced by @Adam Rosenfield or with a quick look on Wikipedia. Nevertheless x86 has release semantics for stores and acquire semantics for loads.
as can be seen in the manual referenced by @Adam Rosenfield or with a quick look on Wikipedia. Nevertheless x86 has release semantics for stores and acquire semantics for loads.
From Kerrek SB's Answer:
What the architectural details mean is that on x86 there will be very little or no extra code generated for operations on atomic word-sized types as long as you ask for at most acquire/release ordering. (Sequential consistency will emit mfence instructions, though.)
Note that sequential consistency is the default! (See for example cppreference).
This means that...
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
void producer()
{
std::string* p = new std::string("Hello");
ptr = p;
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr))
;
assert(*p2 == "Hello"); // never fails
}
(g++ -std=c++11 -S -O3 on x86)
... will actually result in an mfence being emitted in the producer function to account for the aforementioned relaxation on x86 ().
Whereas for...
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
void producer()
{
std::string* p = new std::string("Hello");
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fails
}
(g++ -std=c++11 -S -O3 on x86)
...no mfence will be inserted because x86 has release semantics for stores and acquire semantics for loads.
