Hej everyone
I'm trying to build a lexer used to parse a domain specific language. I have a set of reserved token (fragment RESERVED) and an escape character. The lexer should split whenever a reserved token shows up that is not escaped.
a simplified example:
SEP: ';';
AND: '&&';
fragment ESCAPE: '/';
fragment RESERVED: SEP | AND | ESCAPE;
SINGLETOKEN : (~(RESERVED) | (ESCAPE RESERVED))+;
problem:
This works fine as long as RESERVED only contains single character token. The negation operation ~ only works for single chars.
Unfortunately I need it to work with string token as well. So token with more then 1 character (see AND in the example). Is there a simple way to do so? I need to solve the problem without in-lining java or c code since this has to compile to different languages and I don't want to maintain separate copies.
I hope someone can help me
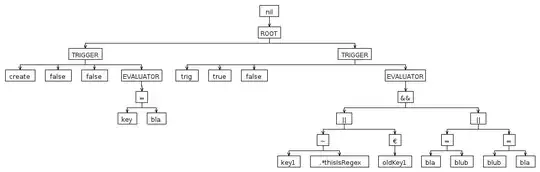
sample input from the whole script
create;false;false;1.key = bla; trig;true;false;(1.key1 ~ .*thisIsRegex || 2.oldKey1 €) && (1.bla=2.blub || 1.blub=bla);
After the Lexer this should look like this | are token seperator whitespaces are not important:|create|;|false|;|false|;|1.|key| = |bla|;| trig|;|true|;|false|;|(|1.|key1| ~| .*thisIsRegex| || |2.|oldKey1| €|)| && |(|1.|bla|=|2.|blub| || |1.|blub|=|bla|)|;|
Whole script can be found on http://pastebin.com/Cz520VW4 (note this link expires in a month) It currently does not work for the regex part yet.
possible but horrible solution
I found a possible solution but its really hacky and makes the script more error prone. So I would prefer to find something cleaner.
What Im currently doing is writing the negation (~RESERVED) by hand.
SEP: ';';
AND: '&&';
fragment ESCAPE: '/';
fragment RESERVED: SEP | AND | ESCAPE;
NOT_RESERVED:
: '&' ~('&' | SEP | ESCAPE)
// any two chars starting with '&' followed by a character other then a reserve character
| ~('&' | SEP | ESCAPE) ~(SEP | ESCAPE)
// other than reserved character followed by '&' followed by any char
;
SINGELTON : (NOT_RESERVED | (ESCAPE RESERVED))+;
The real script has more then 5 multi-character token there might be more later with more then 2 character so this way of solving the problem it will become quite complicated.