Am trying to extract data from reciepts and bills using Tessaract , am using tesseract 3.02 version .
am using only english data , Still the output accuracy is about 60%.
Is there any trained data available which i just replace in tessdata folder
Am trying to extract data from reciepts and bills using Tessaract , am using tesseract 3.02 version .
am using only english data , Still the output accuracy is about 60%.
Is there any trained data available which i just replace in tessdata folder
This is the image nicky provided as a "typical example file":
Looking at it I'd clearly say: "Forget it, nicky! You cannot train Tesseract to recognize 100% of text from this type of image!"
However, you could train yourself to make better photos with your iPhone 3GS (that's the device which was used for the example pictures) from such type of receipts. Here are a few tips:
That said, something like the following ImageMagick command will probably increase Tesseract's recognition rate by some degree:
convert \
https://i.stack.imgur.com/q3Ad4.jpg \
-colorspace gray \
-rotate 90 \
-crop 260x540+110+75 +repage \
-scale 166% \
-normalize \
-colors 32 \
out1.png
It produces the following output:
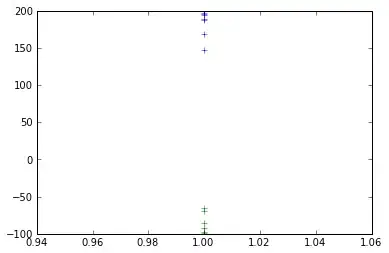
You could even add something like -threshold 30% as the last commandline option to above command to get this:
(You should play a bit with some variations to the 30% value to tweak the result... I don't have the time for this.)
Taking accurate info from a receipt is not impossible with tesseract. You will need to add image filters and some other tools such as OpenCV, NumPy ImageMagick alongside Tesseract. There was a presentation at PyCon 2013 by Franck Chastagnol where he describes how his company did it.
Here is the link: http://pyvideo.org/video/1702/building-an-image-processing-pipeline-with-python
You can get a much cleaner post-processed image before using Tesseract to OCR the text. Try using the Background Surface Thresholding (BST) technique rather than other simple thresholding methods. You can find a white paper on the subject here.
There is an implementation of BST for OpenCV that works pretty well https://stackoverflow.com/a/22127181/3475075
i needed exactly the same thing and i tried some image optimisations to improve the output
you can find my experiment with tessaract here