I'm using OpenCV with CUDA / CUBLAS / CUFFT support to perform some very basic template matching on grayscale screenshots to extract some text, meaning I can assume the following:
I do know the exact size, color and rotation of the raw sprites I'm trying to match, i.e., I have access to the textures that were used in the observed program's rendering process.
However, since the sprites are partially transparent, normal template matching via cv::(gpu::)matchTemplate (using normed cross-correlation) does not work properly, as deviations in transparent regions have too much of a negative influence on the overall correlation.
Basically these examples summarize pretty well what I'm trying to achieve:
Given the template to be matched and its alpha mask:
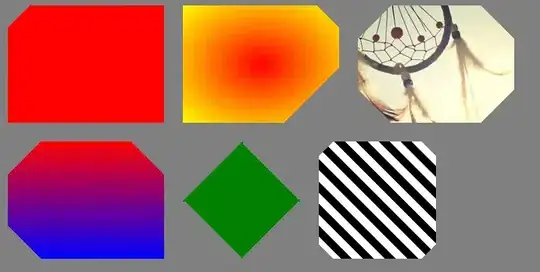
I'd like a high to near 100% match on images like these (arbitrary background, random stuff in transparent regions, partially occluded):

However, images like these should only yield a very low percentage (wrong color, entirely black):
Currently I'm using edge detection to get some decent matches (Canny + cross-correlation) but as you can see, depending on the background, edges may or may not be present in the image, which produces unreliable results and generally matches very "edgy" areas.
I've done some math to come up with an alpha-dependent normed cross-correlation (basically pre-multiplying the alpha mask to both the template and the image) which works fine on paper but is nearly impossible to implement with good performance. And yes, performance is indeed an issue, as multiple sprites (~10) have to be matched in near real-time (~10 FPS) to keep up with the program's speed.
I'm sort of running out of ideas here. Are there any standard approaches to this? Any ideas or suggestions?