Interview Answer
This task is interesting without being too complex, so a great way to start a good technical discussion. My plan to tackle this task would be:
- Split input data in words, using white space and punctuation as delimiters
- Feed every word found into a Trie structure, with counter updated in nodes representing a word's last letter
- Traverse the fully populated tree to find nodes with highest counts
In the context of an interview ... I would demonstrate the idea of Trie by drawing the tree on a board or paper. Start from empty, then build the tree based on a single sentence containing at least one recurring word. Say "the cat can catch the mouse". Finally show how the tree can then be traversed to find highest counts. I would then justify how this tree provides good memory usage, good word lookup speed (especially in the case of natural language for which many words derive from each other), and is suitable for parallel processing.
Draw on the board
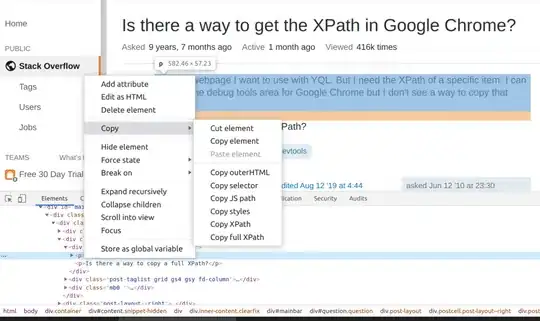
Demo
The C# program below goes through 2GB of text in 75secs on an 4 core xeon W3520, maxing out 8 threads. Performance is around 4.3 million words per second with less than optimal input parsing code. With the Trie structure to store words, memory is not an issue when processing natural language input.
Notes:
- test text obtained from the Gutenberg project
- input parsing code assumes line breaks and is pretty sub-optimal
- removal of punctuation and other non-word is not done very well
- handling one large file instead of several smaller one would require a small amount of code to start reading threads between specified offset within the file.
using System;
using System.Collections.Generic;
using System.Collections.Concurrent;
using System.IO;
using System.Threading;
namespace WordCount
{
class MainClass
{
public static void Main(string[] args)
{
Console.WriteLine("Counting words...");
DateTime start_at = DateTime.Now;
TrieNode root = new TrieNode(null, '?');
Dictionary<DataReader, Thread> readers = new Dictionary<DataReader, Thread>();
if (args.Length == 0)
{
args = new string[] { "war-and-peace.txt", "ulysees.txt", "les-miserables.txt", "the-republic.txt",
"war-and-peace.txt", "ulysees.txt", "les-miserables.txt", "the-republic.txt" };
}
if (args.Length > 0)
{
foreach (string path in args)
{
DataReader new_reader = new DataReader(path, ref root);
Thread new_thread = new Thread(new_reader.ThreadRun);
readers.Add(new_reader, new_thread);
new_thread.Start();
}
}
foreach (Thread t in readers.Values) t.Join();
DateTime stop_at = DateTime.Now;
Console.WriteLine("Input data processed in {0} secs", new TimeSpan(stop_at.Ticks - start_at.Ticks).TotalSeconds);
Console.WriteLine();
Console.WriteLine("Most commonly found words:");
List<TrieNode> top10_nodes = new List<TrieNode> { root, root, root, root, root, root, root, root, root, root };
int distinct_word_count = 0;
int total_word_count = 0;
root.GetTopCounts(ref top10_nodes, ref distinct_word_count, ref total_word_count);
top10_nodes.Reverse();
foreach (TrieNode node in top10_nodes)
{
Console.WriteLine("{0} - {1} times", node.ToString(), node.m_word_count);
}
Console.WriteLine();
Console.WriteLine("{0} words counted", total_word_count);
Console.WriteLine("{0} distinct words found", distinct_word_count);
Console.WriteLine();
Console.WriteLine("done.");
}
}
#region Input data reader
public class DataReader
{
static int LOOP_COUNT = 1;
private TrieNode m_root;
private string m_path;
public DataReader(string path, ref TrieNode root)
{
m_root = root;
m_path = path;
}
public void ThreadRun()
{
for (int i = 0; i < LOOP_COUNT; i++) // fake large data set buy parsing smaller file multiple times
{
using (FileStream fstream = new FileStream(m_path, FileMode.Open, FileAccess.Read))
{
using (StreamReader sreader = new StreamReader(fstream))
{
string line;
while ((line = sreader.ReadLine()) != null)
{
string[] chunks = line.Split(null);
foreach (string chunk in chunks)
{
m_root.AddWord(chunk.Trim());
}
}
}
}
}
}
}
#endregion
#region TRIE implementation
public class TrieNode : IComparable<TrieNode>
{
private char m_char;
public int m_word_count;
private TrieNode m_parent = null;
private ConcurrentDictionary<char, TrieNode> m_children = null;
public TrieNode(TrieNode parent, char c)
{
m_char = c;
m_word_count = 0;
m_parent = parent;
m_children = new ConcurrentDictionary<char, TrieNode>();
}
public void AddWord(string word, int index = 0)
{
if (index < word.Length)
{
char key = word[index];
if (char.IsLetter(key)) // should do that during parsing but we're just playing here! right?
{
if (!m_children.ContainsKey(key))
{
m_children.TryAdd(key, new TrieNode(this, key));
}
m_children[key].AddWord(word, index + 1);
}
else
{
// not a letter! retry with next char
AddWord(word, index + 1);
}
}
else
{
if (m_parent != null) // empty words should never be counted
{
lock (this)
{
m_word_count++;
}
}
}
}
public int GetCount(string word, int index = 0)
{
if (index < word.Length)
{
char key = word[index];
if (!m_children.ContainsKey(key))
{
return -1;
}
return m_children[key].GetCount(word, index + 1);
}
else
{
return m_word_count;
}
}
public void GetTopCounts(ref List<TrieNode> most_counted, ref int distinct_word_count, ref int total_word_count)
{
if (m_word_count > 0)
{
distinct_word_count++;
total_word_count += m_word_count;
}
if (m_word_count > most_counted[0].m_word_count)
{
most_counted[0] = this;
most_counted.Sort();
}
foreach (char key in m_children.Keys)
{
m_children[key].GetTopCounts(ref most_counted, ref distinct_word_count, ref total_word_count);
}
}
public override string ToString()
{
if (m_parent == null) return "";
else return m_parent.ToString() + m_char;
}
public int CompareTo(TrieNode other)
{
return this.m_word_count.CompareTo(other.m_word_count);
}
}
#endregion
}
Here the output from processing the same 20MB of text 100 times across 8 threads.
Counting words...
Input data processed in 75.2879952 secs
Most commonly found words:
the - 19364400 times
of - 10629600 times
and - 10057400 times
to - 8121200 times
a - 6673600 times
in - 5539000 times
he - 4113600 times
that - 3998000 times
was - 3715400 times
his - 3623200 times
323618000 words counted
60896 distinct words found