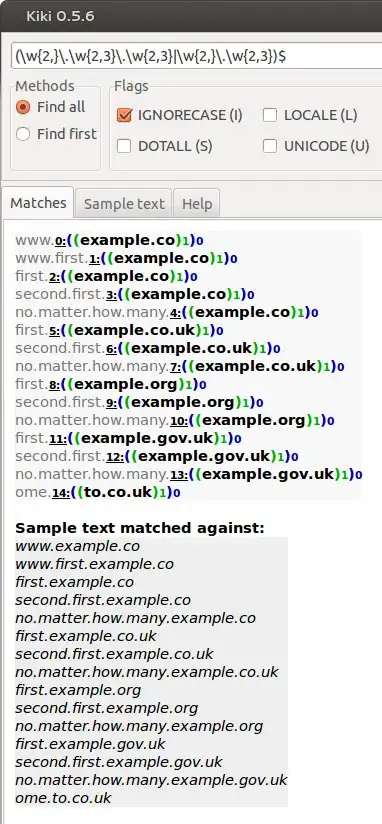
I need to be able to identify a domain name of any subdomain.
Examples:
For all of thiese I need to match only example.co / example.com / example.org / example.co.uk / example.com.au / example.gov.us and so on
www.example.co
www.first.example.co
first.example.co
second.first.example.co
no.matter.how.many.example.co
first.example.co.uk
second.first.example.co.uk
no.matter.how.many.example.co.uk
first.example.org
second.first.example.org
no.matter.how.many.example.org
first.example.gov.uk
second.first.example.gov.uk
no.matter.how.many.example.gov.uk
I have been playing with regular expressions all day and been Googleing for something all day long and still can't seem to find something.
Edit2: I prefer a regex that might fail for very odd cases like t.co then list all TLD's and have the ones I did not list but could have been predicted fail and match more then it should. Isn't this be the option you would chose?
Update: Using the chosen answer as a guide I have constructed this regex that does the job for me.
/([0-9a-z-]{2,}\.[0-9a-z-]{2,3}\.[0-9a-z-]{2,3}|[0-9a-z-]{2,}\.[0-9a-z-]{2,3})$/i
It might not be perfect but so far I have not encountered a case where it fails.