I have a document which has been sloppily authored. It's a dictionary that contains cyrillic characters. Most of the dictionary is manageable, but I'm stuck with one thing I need help with. Words have accented letters in them and they're mostly formatted properly as a letter with a unicode accent (thus forming a single letter). However there are some very peculiar letters that look similar for example to: a;´ (where "a" is any arbitrary cyrillic letter). You'd expect á in its place. However it wouldn't be a problem per se if only this thing could be exported to, say HTML and manipulated in a text editor. The problem is that Word treats this "thing" as a single character/entity and
- when exporting it is COMPLETELY omitted
- when copied it can only be pasted into Notepad (which translates it into three separate characters), when being pasted into WordPad it just won't appear at all.
- when a search is run in Word it won't find the letter, neither the actual character nor the exactly copied/pasted combination.
- the letter will disappear when the document is opened in any other software, such as Libre Office
At this point I'm trying to:
- understand what this combination is exactly
- run a search/replace operation to find and weed out all of those errors
Here's a sample Word file.
Here's a screenshot of the word/letter in question:
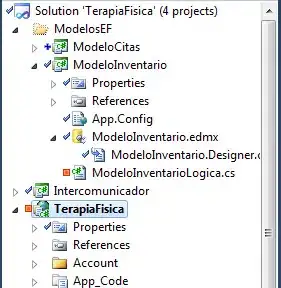
which when typed correctly should appear like "скре́пка".