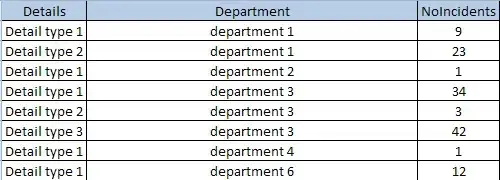
I have the following basic SQL statement which uses the PIVOT command.
SELECT *
FROM
(
--select statement that creates my dataset
) s
PIVOT (Max(incidentcount) for dept in ([dept1],[dept2])) p
This does what I expect it to do, it gives me a count of incidents per reason with depts as my columns. My problem is the departments that I am using for my columns go from 1-60.
Is there anyway I can tell the query to use the column Department to populate the PIVOT in part. Obviously I want to avoid manually typing each department.
EDIT
This is the sql that creates my dataset that I use in the pivot...
SELECT Details, Department , count(*) NoIncidents
FROM myincidentdb
Group by Details, Department
EDIT 2