Here is a pretty good explanation of the different types of messaging semantics for your second question:
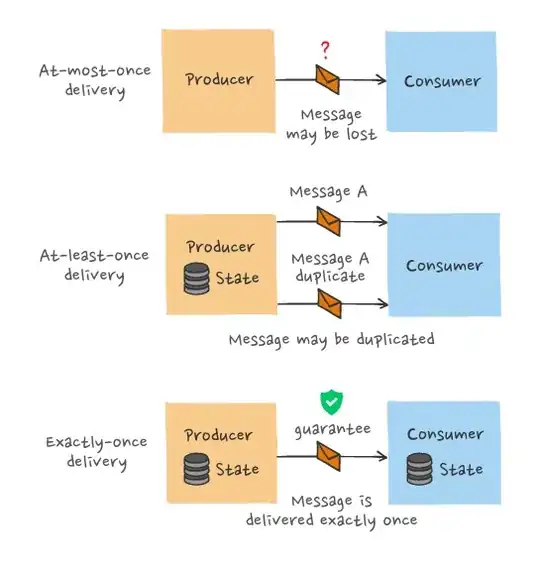
At-most-once semantics: The easiest type of semantics to achieve, from an engineering complexity perspective, since it can be done in a fire-and-forget way. There's rarely any need for the components of the system to be stateful. While it's the easiest to achieve, at-most-once is also the least desirable type of messaging semantics. It provides no absolute message delivery guarantees since each message is delivered once (best case scenario) or not at all.
At-least-once semantics: This is an improvement on at-most-once semantics. There might be multiple attempts at delivering a message, so at least one attempt is successful. In other words, there's a chance messages may be duplicated, but they can't be lost. While not ideal as a system-wide characteristic, at-least-once semantics are good enough for use cases where duplication of data is of little concern or scenarios where deduplication is possible on the consumer side.
Exactly-once semantics: The ultimate message delivery guarantee and the optimal choice in terms of data integrity. As its name suggests, exactly-once semantics means that each message is delivered precisely once. The message can neither be lost nor delivered twice (or more times). Exactly-once is by far the most dependable message delivery guarantee. It’s also the hardest to achieve.
That's all part of this blog post about Exactly-once message processing (Disclosure: I work for Ably)
Hope this helps