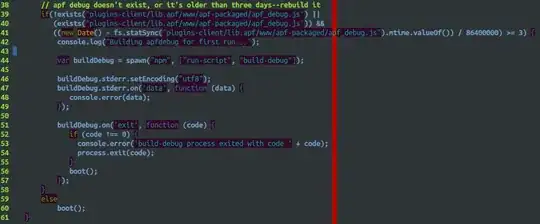
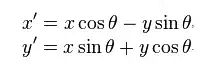How can I threshold this blurry image to make the digits as clear as possible?
In a previous post, I tried adaptively thresholding a blurry image (left), which resulted in distorted and disconnected digits (right):
Since then, I've tried using a morphological closing operation as described in this post to make the brightness of the image uniform:
If I adaptively threshold this image, I don't get significantly better results. However, because the brightness is approximately uniform, I can now use an ordinary threshold:
This is a lot better than before, but I have two problems:
- I had to manually choose the threshold value. Although the closing operation results in uniform brightness, the level of brightness might be different for other images.
- Different parts of the image would do better with slight variations in the threshold level. For instance, the 9 and 7 in the top left come out partially faded and should have a lower threshold, while some of the 6s have fused into 8s and should have a higher threshold.
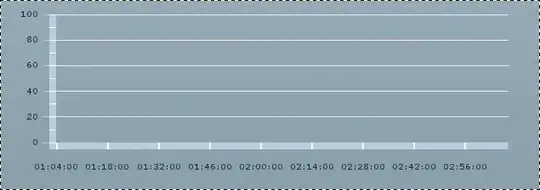
I thought that going back to an adaptive threshold, but with a very large block size (1/9th of the image) would solve both problems. Instead, I end up with a weird "halo effect" where the centre of the image is a lot brighter, but the edges are about the same as the normally-thresholded image:

Edit: remi suggested morphologically opening the thresholded image at the top right of this post. This doesn't work too well. Using elliptical kernels, only a 3x3 is small enough to avoid obliterating the image entirely, and even then there are significant breakages in the digits:

Edit2: mmgp suggested using a Wiener filter to remove blur. I adapted this code for Wiener filtering in OpenCV to OpenCV4Android, but it makes the image even blurrier! Here's the image before (left) and after filtering with my code and a 5x5 kernel:
Here is my adapted code, which filters in-place:
private void wiener(Mat input, int nRows, int nCols) { // I tried nRows=5 and nCols=5
Mat localMean = new Mat(input.rows(), input.cols(), input.type());
Mat temp = new Mat(input.rows(), input.cols(), input.type());
Mat temp2 = new Mat(input.rows(), input.cols(), input.type());
// Create the kernel for convolution: a constant matrix with nRows rows
// and nCols cols, normalized so that the sum of the pixels is 1.
Mat kernel = new Mat(nRows, nCols, CvType.CV_32F, new Scalar(1.0 / (double) (nRows * nCols)));
// Get the local mean of the input. localMean = convolution(input, kernel)
Imgproc.filter2D(input, localMean, -1, kernel, new Point(nCols/2, nRows/2), 0);
// Get the local variance of the input. localVariance = convolution(input^2, kernel) - localMean^2
Core.multiply(input, input, temp); // temp = input^2
Imgproc.filter2D(temp, temp, -1, kernel, new Point(nCols/2, nRows/2), 0); // temp = convolution(input^2, kernel)
Core.multiply(localMean, localMean, temp2); //temp2 = localMean^2
Core.subtract(temp, temp2, temp); // temp = localVariance = convolution(input^2, kernel) - localMean^2
// Estimate the noise as mean(localVariance)
Scalar noise = Core.mean(temp);
// Compute the result. result = localMean + max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
Core.max(temp, noise, temp2); // temp2 = max(localVariance, noise)
Core.subtract(temp, noise, temp); // temp = localVariance - noise
Core.max(temp, new Scalar(0), temp); // temp = max(0, localVariance - noise)
Core.divide(temp, temp2, temp); // temp = max(0, localVar-noise) / max(localVariance, noise)
Core.subtract(input, localMean, input); // input = input - localMean
Core.multiply(temp, input, input); // input = max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
Core.add(input, localMean, input); // input = localMean + max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
}