I use Tortoise SVN usuallly, but I have been looking into Mercurial since it is a distributed revision control system.
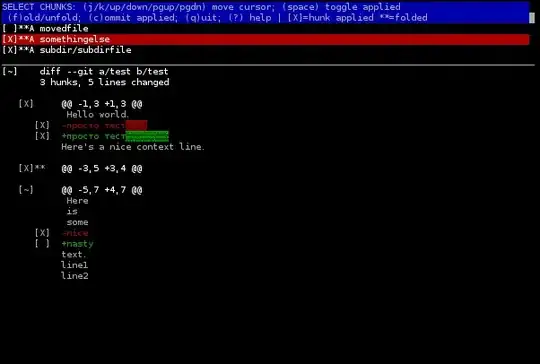
What I am looking for, in both systems, is a tool that let me pick only parts of a file and commit them. If I want to do this now, I have to copy to a temp version of the file and keep only the changes I want to commit in the current version, and then copy the temp version to the current version again after committing. It's just such a hassle and the program should be able to do this for me.
I heard Git supports this, please let me know if this is correct.