I have a processed captcha image(Enlarged) look like :
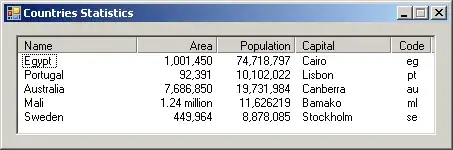
As you can see, the font-size of the "TEXT" is bit larger than the width of the Noisy Lines.
So I need an algorithm or code to remove the noisy lines from this image.
With the help of Python PIL Library and the chopping algorithm mentioned below I din't get the output image which could be easily read by OCRs.
Here's Python code that I tried :
import PIL.Image
import sys
# python chop.py [chop-factor] [in-file] [out-file]
chop = int(sys.argv[1])
image = PIL.Image.open(sys.argv[2]).convert('1')
width, height = image.size
data = image.load()
# Iterate through the rows.
for y in range(height):
for x in range(width):
# Make sure we're on a dark pixel.
if data[x, y] > 128:
continue
# Keep a total of non-white contiguous pixels.
total = 0
# Check a sequence ranging from x to image.width.
for c in range(x, width):
# If the pixel is dark, add it to the total.
if data[c, y] < 128:
total += 1
# If the pixel is light, stop the sequence.
else:
break
# If the total is less than the chop, replace everything with white.
if total <= chop:
for c in range(total):
data[x + c, y] = 255
# Skip this sequence we just altered.
x += total
# Iterate through the columns.
for x in range(width):
for y in range(height):
# Make sure we're on a dark pixel.
if data[x, y] > 128:
continue
# Keep a total of non-white contiguous pixels.
total = 0
# Check a sequence ranging from y to image.height.
for c in range(y, height):
# If the pixel is dark, add it to the total.
if data[x, c] < 128:
total += 1
# If the pixel is light, stop the sequence.
else:
break
# If the total is less than the chop, replace everything with white.
if total <= chop:
for c in range(total):
data[x, y + c] = 255
# Skip this sequence we just altered.
y += total
image.save(sys.argv[3])
So, basically I would like to know a better algorithm/code to get rid of the noise and thus able to make the image readable by the OCR (Tesseract or pytesser).