Suppose I have the below table
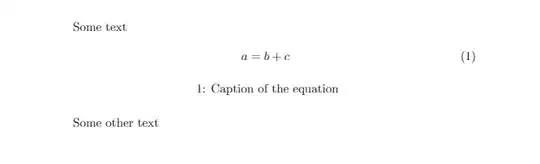
CREATE TABLE [dbo].[TestData](
[ID] [bigint] NOT NULL,
[InstanceID] [int] NOT NULL,
[Field] [int] NULL,
[UserID] [bigint] NOT NULL
) ON [PRIMARY]
GO
INSERT [dbo].[TestData] ([ID], [InstanceID], [Field], [UserID])
VALUES (1, 1, NULL, 1000),(2, 1, NULL, 1002),(3, 1, NULL, 1000),
(4, 1, NULL, 1003),(5, 2, NULL, 1002), (6, 2, NULL, 1005),
(7, 2, NULL, 1006),(8, 2, NULL, 1007),(9, 3, NULL, 1002),
(10, 3, NULL, 1006),(11, 3, NULL, 1009),(12, 3, NULL, 1010),
(13, 1, NULL, 1006),(14, 2, NULL, 1002),(15, 3, NULL, 1003)
GO
I search for the best practice to write a query to get the full rows of intersected data between two instances using UserID
For example the intersected UserIDs between InstanceID 1 and 2 are ( 1002 , 1006 ), to get the results I wote the query in two different ways as below :
Select * From TestData
Where UserID in
(
Select T1.UserID From TestData T1 Where InstanceID = 1
Intersect
Select T2.UserID From TestData T2 Where InstanceID = 2
)
and InstanceID in (1,2) Order By 1
Second
Select * From TestData
Where UserID in
(
Select Distinct T1.UserID
From TestData T1 join TestData T2 on T1.UserID = T2.UserID
Where T1.InstanceID = 1 and T2.InstanceID = 2
)
and InstanceID in (1,2) Order By 1
So the results will be
Is one of the above queries is the best way to get the results ??