I want to create some sample programs that deal with encodings, specifically I want to use wide strings like:
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
Because these are example programs.
This is absolutely trivial with gcc that treats source code as UTF-8 encoded text. But, straightforward compilation does not work under MSVC. I know that I can encode them using escape sequences but I would prefer to keep them as readable text.
Is there any option that I can specify as command line switch for "cl" in order to
make this work? There are there any command line switch like gcc'c -finput-charset?
If not how would you suggest make the text natural for user?
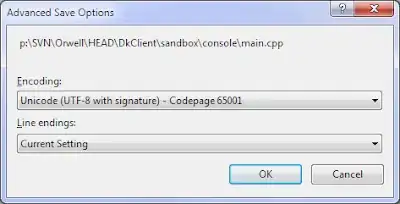
Note: adding BOM to UTF-8 file is not an option because it becomes non-compilable by other compilers.
Note2: I need it to work in MSVC Version >= 9 == VS 2008
The real answer: There is no solution