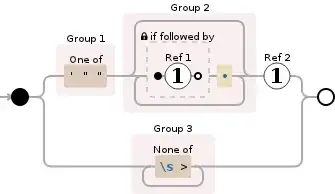
Please can someone help me understand this regular expression used to match src attributes of img tags in HTML?
src=(?:(['""])(?<src>(?:(?!\1).)*)\1|(?<src>[^\s>]+))
src= this is easy
(?:(['""])(?<src>(?:(?!\1).)*) ?: is unknown (['""]) matches either single or double quotes, followed by a named group "src" that matches unknown strings
\1 unknown
| "or"
(?<src>[^\s>]+)) named group "src" matches one or more of line start or whitespace
In brief what does ?: mean?
So (?:...) is a non-capturing version of regular parentheses. Matches whatever regular expression is inside the parentheses, but the substring matched by the group cannot be retrieved after performing a match or referenced later in the pattern.
Thanks @mbratch
what does \1 mean?
And finally, does the exclamation mark have any special significance here? (negation?)