Why build a parse tree it all? It's relatively straightforward to convert a regular expression straight to a NFA.
There are a finite number of base cases. Knowing these, we can build the full NFA from some combination of these cases.

Consider all possible ways some regular expression R can be constructed.
The first three are easy, but union, concatenation, and Kleene closure require a little thought.
I found pretty good pictures for the last 3 here:
http://www.codeproject.com/KB/recipes/OwnRegExpressionsParser/Thompson.jpg
R = Ø (Accepts nothing): 
Will trivially be a path to a non-accepting state. (Let O be non-accepting state and X be accepting.)
(->O)
R = ϵ (Accepts the empty string):
Path to an accepting state.
(->X)
R = a (Accepts the string 'a'):
A start state with a path on the string 'a' to an accepting state.
(->O-a>X)
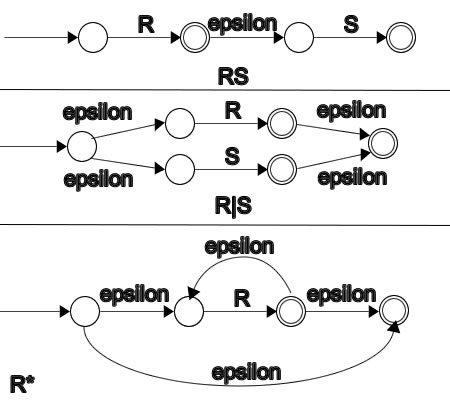
R = R1 ∘ R2 (Concatenation of 2 regular expressions):
Start state becomes the start state of R1, epsilon transition added between the accepting state of R1 and the start state of R2, accepting state from R1 is removed. In the figure, the second state is accepting but it should not be.
R = R1 U R2 (Union of 2 regular expressions):
A start state with an epsilon transition to the NFAs for R1 and R2 -- the machine will "guess" which one to enter to be accepted if possible. In the figure, R1 and R2 are represented by R and S.
R = R1* (Kleene closure of R1):
Add an epsilon transition so R1 can loop forever!
Now that we have formulations for all of the initial possibilities, they can be combined into one large NFA. For example, for (A U B) ∘ C*
- Build the NFA 'x' for A U B.
- Build the NFA 'y' for C*.
- Build the NFA x ∘ y
- You're done!
One can prove that any NFA can be inductively constructed like this, and that all of the initial constructions that I provided are correct. Meh.
I am sadly not familiar with any js tools that will do what you're asking, but with the information above, if you store the base cases using some reasonable representation, the code should be fairly simple.
For a much more thorough and less sleep-deprived explanation, try http://www.codeproject.com/Articles/5412/Writing-own-regular-expression-parser
You'll want to really understand Thompson's algorithm (what I've described) before you delve into coding. The site looks like it goes into much more depth about implementation than I do here.
Good luck!
{kind=link}