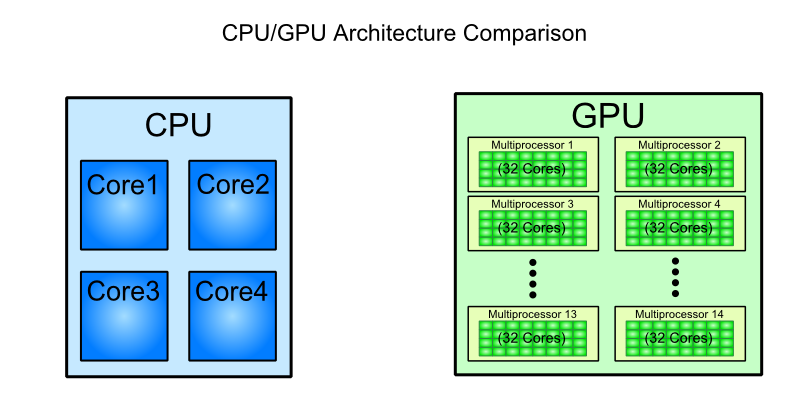
I have a presentation to make to people who have (almost) no clue of how a GPU works. I think saying that a GPU has a thousand cores where a CPU only has four to eight of them is a non-sense. But I want to give my audience an element of comparison.
After a few months working with NVidia's Kepler and AMD's GCN architectures, I'm tempted to compare a GPU "core" to a CPU's SIMD ALU (I don't know if they have a name for that at Intel). Is it fair ? After all, when looking at an assembly level, those programming models have much in common (at least with GCN, take a look at p2-6 of the ISA manual).
This article states that an Haswell processor can do 32 single-precision operations per cycle, but I suppose there is pipelining or other things happening to achieve that rate. In NVidia parlance, how many Cuda-cores does this processor have ? I would say 8 per CPU-core for 32 bits operations, but this is just a guess based on the SIMD width.
Of course there is many other things to take into account when comparing CPU and GPU hardware, but this is not what I'm trying to do. I just have to explain how the thing is working.
PS: All pointers to CPU hardware documentations or CPU/GPU presentations are greatly appreciated !
EDIT: Thanks for your answers, sadly I had to chose only one of them. I marked Igor's answer because it sticks the most to my initial question and gave me enough informations to justify why this comparison shouldn't be taken too far, but CaptainObvious provided very good articles.
{kind=link}