Using the power of debuggex to generate you an image :)
<(\/?)(\w+)([^>]*?)>
Will be evaluated like this
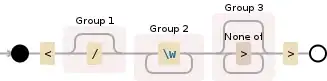
Edit live on Debuggex
As you can see, it matches HTML-tags (opening and closing tags). The regex contains three capture groups, capturing the following:
(\/?) existence of / (it's a closing tag, if present)(\w+) name of the tag([^>]*?) everything else until the tag closes (e.g. attributes)
This way it matches <a href="#">. Interestingly it does not match <a data-fun="fun>nofun"> correctly because it stops at the > within the data-fun attribute. Although (I think) > is valid in an attribute value.
Another funny thing is, that the tag-name capture, does not capture all theoretically valid XHTML tags. XHTML allows Letter | Digit | '.' | '-' | '_' | ':' | .. (source: XHTML spec). (\w+), however, does not match ., -, and :. An imaginary <.foobar> tag will not be matched by this regex. This should not have any real life impact, though.
You see that parsing HTML using RgExes is a risky thing. You might be better of with a HTML parser.