When I try to overlap data transfers and kernel execution It seems like the card is executing all memory transfers in-order, no matter what stream I use.
So, If I issue the following:
- stream 1: MemcpyA_HtoD_1; Kernel_1; MemcpyA_DtoH_1
- stream 2: MemcpyA_HtoD_2; Kernel_2; MemcpyA_DtoH_2
The MemcpyA_HtoD_2 will wait till the MemcpyA_DtoH_1 is completed. So no overlapping is achieved. No matter what config of streams I use, the Memcpy operations are always issued in order. So the only way for achieving overlapping involves buffering the outputs or delaying the output transfer till the next iteration.
I use CUDA 5.5, windows 7 x64 and a GTX Titan. All cpu memory is pinned and data_transfers are done using the async version.
See the following screens with the behavior:
issuing, host_to_device -> kernel -> device_to_host (normal behavior) and can not get overlap.
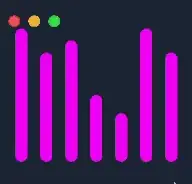
issuing host_to_device -> kernel (avoiding device_to_host after kernel) gets overlap ... because all memory copies are executed in-order, no matter what stream configuration I try.
UPDATE
If someone is interested in reproducing this issue, I have coded a synthetic program that shows this undesired behavior. Its a complete VS2010 solution using CUDA 5.5
VS2010 Streams Not Working link
Could someone execute this on linux for testing overlapping?
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#define N 1024*1024
__global__ void someKernel(int *d_in, int *d_out) {
for (int i = threadIdx.x; i < threadIdx.x + 1024; i++) {
d_out[i] = d_in[i];
}
}
int main () {
int *h_bufferIn[100];
int *h_bufferOut[100];
int *d_bufferIn[100];
int *d_bufferOut[100];
//allocate some memory
for (int i = 0; i < 100; i++) {
cudaMallocHost(&h_bufferIn[i],N*sizeof(int));
cudaMallocHost(&h_bufferOut[i],N*sizeof(int));
cudaMalloc(&d_bufferIn[i], N*sizeof(int));
cudaMalloc(&d_bufferOut[i], N*sizeof(int));
}
//create cuda streams
cudaStream_t st[2];
cudaStreamCreate(&st[0]);
cudaStreamCreate(&st[1]);
//trying to overlap computation and memcpys
for (int i = 0; i < 100; i+=2) {
cudaMemcpyAsync(d_bufferIn[i], h_bufferIn[i], N*sizeof(int), cudaMemcpyHostToDevice, st[i%2]);
someKernel<<<1,256, 0, st[i%2]>>>(d_bufferIn[i], d_bufferOut[i]);
cudaMemcpyAsync(h_bufferOut[i], d_bufferOut[i], N*sizeof(int), cudaMemcpyDeviceToHost, st[i%2]);
cudaStreamQuery(0);
cudaMemcpyAsync(d_bufferIn[i+1], h_bufferIn[i+1], N*sizeof(int), cudaMemcpyHostToDevice, st[(i+1)%2]);
someKernel<<<1,256, 0, st[(i+1)%2]>>>(d_bufferIn[i+1], d_bufferOut[i+1]);
cudaMemcpyAsync(h_bufferOut[i+1], d_bufferOut[i+1], N*sizeof(int), cudaMemcpyDeviceToHost, st[(i+1)%2]);
cudaStreamQuery(0);
}
cudaDeviceSynchronize();
}