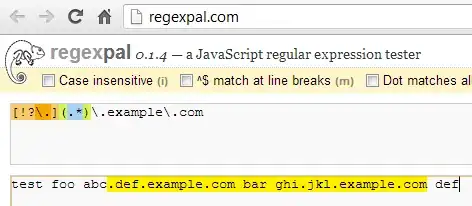
Just on a side note, while HamZa's answer works for your current sample code, if you need to make sure that the domain names are also valid, you might want to try a different approach, since [^.\s]+ will match ANY character that is not a space or a . (for example, that regex will match jk&^%&*(l.example.com as a "valid" subdomain).
Since there are far fewer valid characters for domain name values than there are invalid ones, you might consider using an "additive" approach to the regex, rather than subtractive. This pattern here is probably the one that you are looking for for valid domain names: /(?:[\s.])([a-z0-9][a-z0-9-]+[a-z0-9]\.example\.com)/gi
To break it down a little more . . .
(?:[\s.]) - matches the space or . that would mark the beginning of the loweset level subdomain([a-z0-9][a-z0-9-]+[a-z0-9]\.example\.com) - this captures a group of letters, numbers or dashes, that must begin and end with a letter or a number (domain name rules), and then the example.com domain.gi - makes the regex pattern greedy and case insensitive
At this point, it simply a question of grabbing the matches. Since .match() doesn't play well with the regex "non-capturing groups", use .exec() instead:
var domainString = "test foo abc.def.example.com bar ghi.jkl.example.com def";
var regDomainPattern = /(?:[\s.])([a-z0-9][a-z0-9-]+[a-z0-9]\.example\.com)/gi;
var aMatchedDomainStrings = [];
var patternMatch;
// loop through as long as .exec() still gets a match, and take the second index of the result (the one that ignores the non-capturing groups)
while (null != (patternMatch = regDomainPattern.exec(domainString))) {
aMatchedDomainStrings.push(patternMatch[1]);
}
At that point aMatchedDomainStrings should contain all of your valid, first-level, sub-domains.
var domainString = "test foo abc.def.example.com bar ghi.jkl.example.com def";
. . . should get you: def.example.com and jkl.example.com, while:
var domainString = "test foo abc.def.example.com bar ghi.jk&^%&*(l.example.com def";
. . . should get you only: def.example.com