I can reproduce this issue with the following
CREATE TABLE dbo.TargetTable(Id int IDENTITY PRIMARY KEY, Value INT)
CREATE TABLE dbo.BulkTable(Id int IDENTITY PRIMARY KEY, Value INT)
INSERT INTO dbo.BulkTable
SELECT TOP (1000000) 1
FROM sys.all_objects o1, sys.all_objects o2
DECLARE @TargetTableMapping TABLE (BulkId INT,TargetId INT);
MERGE dbo.TargetTable T
USING dbo.BulkTable S
ON 0 = 1
WHEN NOT MATCHED THEN
INSERT (Value)
VALUES (Value)
OUTPUT S.Id AS BulkId,
inserted.Id AS TargetId
INTO @TargetTableMapping;
This gives a plan with a sort before the clustered index merge operator.
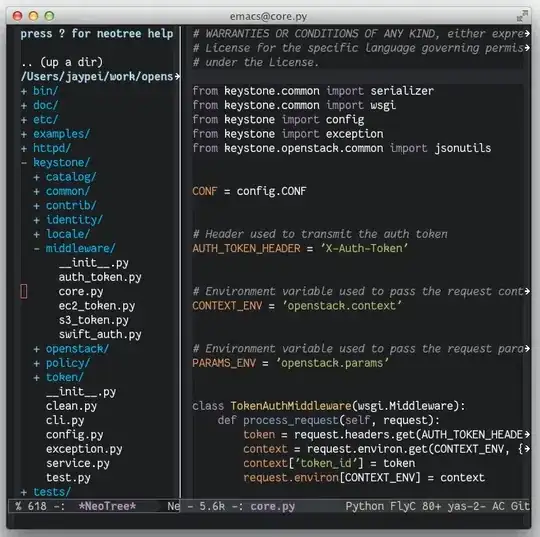
The sort is on Expr1011, Action1010 which are both computed columns output from previous operators.
Expr1011 is the result of calling the internal and undocumented function getconditionalidentity to produce an id column for the identity column in TargetTable.
Action1010 is a flag indicating insert, update, delete. It is always 4 in this case as the only action this MERGE statement can perform is INSERT.
The reason the sort is in the plan is because the clustered index merge operator has the DMLRequestSort property set.
The DMLRequestSort property is set based on the number of rows expected to be inserted. Paul White explains in the comments here
[DMLRequestSort] was added to support the ability to minimally-log
INSERT statements in 2008. One of the preconditions for minimal
logging is that the rows are presented to the Insert operator in
clustered key order.
Inserting into tables in clustered index key order can be more efficient anyway as it reduces random IO and fragmentation.
If the function getconditionalidentity returns generated identity values in ascending order (as would seem reasonable) then the input to the sort will already be in the desired order. The sort in the plan would in that case be logically redundant, (there was previously a similar issue with unnecessary sorts with NEWSEQUENTIALID)
It is possible to get rid of the sort by making the expression a bit more opaque.
DECLARE @TargetTableMapping TABLE (BulkId INT,TargetId INT);
DECLARE @N BIGINT = 0x7FFFFFFFFFFFFFFF
MERGE dbo.TargetTable T
USING (SELECT TOP(@N) * FROM dbo.BulkTable) S
ON 1=0
WHEN NOT MATCHED THEN
INSERT (Value)
VALUES (Value)
OUTPUT S.Id AS BulkId,
inserted.Id AS TargetId
INTO @TargetTableMapping;
This reduces the estimated row count and the plan no longer has a sort. You will need to test whether or not this actually improves performance though. Possibly it might make things worse.
 !
!