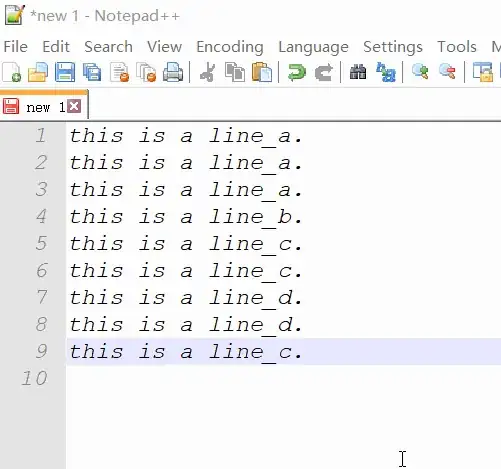
I found many results but for some reason nothing works for me! I've tried preg_replace with regex and also html_entity_decode, but no good...
I want to select words that has a hash mark prefix e.g. #WORD, which works just fine, but sometimes the hash mark is read as ‏#WORD and it misses up.
Example:
This is a normal #hash_mark but #this_isn't
as it appears:
The regex I use to select words with hash mark prefix '~(?<=\s|^)#[^\s#]++~um'
In the question marked as a duplicate, the answer doesn't work for Unicode text, as seen in the image: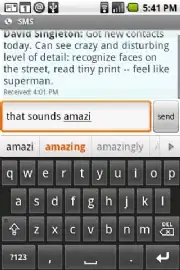
The code does remove all special characters including Unicode text, what's required is only to replace the ‏# with a normal #
function remove_special_char($sentence){
return preg_replace('/[^a-zA-Z0-9_ %\[\]\.\(\)%&-]/s','',$sentence);
}
echo remove_special_char("hello مرحبا привет שלום");
Output:
hello