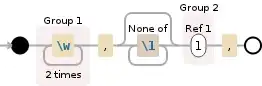
I have a list of two character values, each on its own line in Notepad++. I am trying to eliminate the duplicates, but what I have written is only matching characters that are one line apart.
So if my list looks like this:
ME, <- not matched
OR, |
ME, <- not matched
RI,
IL,
SD,
NV,
VA,
VA,
NY,
MN,
IL,
CA,
MI,
MO, <- match
MO, <- match
Right now I am using this. How can I modify it so it finds duplicated results more that one line apart as well
((\w{2}).*(\r\n)(\2))+
EDIT
((\w{2}).*(\r\n))(.*\r\n)+\1 This seems to work a bit better.