This topic has been addressed for text based emoticons at link1, link2, link3. However, I would like to do something slightly different than matching simple emoticons. I'm sorting through tweets that contain the emoticons' icons. The following unicode information contains just such emoticons: pdf.
Using a string with english words that also contains any of these emoticons from the pdf, I would like to be able to compare the number of emoticons to the number of words.
The direction that I was heading down doesn't seem to be the best option and I was looking for some help. As you can see in the script below, I was just planning to do the work from the command line:
$cat <file containing the strings with emoticons> | ./emo.py
emo.py psuedo script:
import re
import sys
for row in sys.stdin:
print row.decode('utf-8').encode("ascii","replace")
#insert regex to find the emoticons
if match:
#do some counting using .split(" ")
#print the counting
The problem that I'm running into is the decoding/encoding. I haven't found a good option for how to encode/decode the string so I can correctly find the icons. An example of the string that I want to search to find the number of words and emoticons is as follows:
"Smiley emoticon rocks!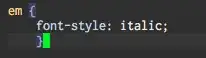 I like you
I like you ."
."
The challenge: can you make a script that counts the number of words and emoticons in this string? Notice that the emoticons are both sitting next to the words with no space in between.