I have the following problem: I need to compute the inclusive scans (e.g. prefix sums) of values based on a tree structure on the GPU. These scans are either from the root node (top-down) or from the leaf nodes (bottom-up). The case of a simple chain is easily handled, but the tree structure makes parallelization rather difficult to implement efficiently.
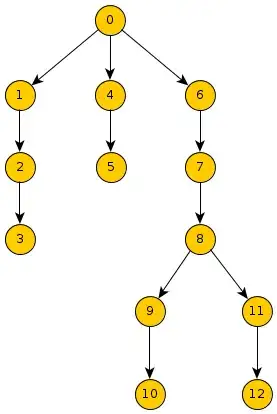
For instance, after a top-down inclusive scan, (12) would hold (0)[op](6)[op](7)[op](8)[op](11)[op](12), and for a bottom-up inclusive scan, (8) would hold (8)[op](9)[op](10)[op](11)[op](12), where [op] is a given binary operator (matrix addition, multiplication etc.).
One also needs to consider the following points:
- For a typical scenario, the length of the different branches should not be too long (~10), with something like 5 to 10 branches, so this is something that will run inside a block and work will be split between the threads. Different blocks will simply handle different values of nodes. This is obviously not optimal regarding occupancy, but this is a constraint on the problem that will be tackled sometime later. For now, I will rely on Instruction-level parallelism.
- The structure of the graph cannot be changed (it describes an actual system), thus it cannot be balanced (or only by changing the root of the tree, e.g. using
(6)as the new root). Nonetheless, a typical tree should not be too unbalanced. - I currently use CUDA for GPGPU, so I am open to any CUDA-enabled template library that can solve this issue.
- Node data is already in global memory and the result will be used by other CUDA kernels, so the objective is just to achieve this without making it a huge bottleneck.
- There is no "cycle", i.e. branches cannot merge down the tree.
- The structure of the tree is fixed and set in an initialization phase.
- A single binary operation can be quite expensive (e.g. multiplication of polynomial matrices, i.e. each element is a polynomial of a given order).
In this case, what would be the "best" data structure (for the tree structure) and the best algorithms (for the inclusive scans/prefix sums) to solve this problem?