My Problem
I'm attempting to crawl the individual links on the US House of Representatives Site to find Washington addresses for all of the listed individuals. The problem is that the format of the Washington address varies from time to time. Sometimes there are bullets, pipes, new lines and break-tags making it difficult to match.
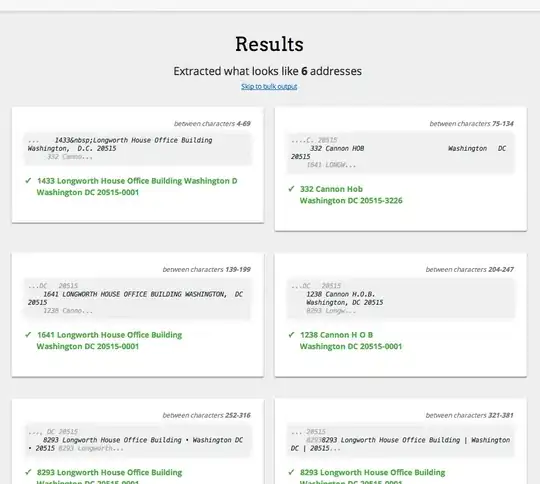
I'm attempting to crawl many pages to retrieve addresses which are largely similar:
ignore peculiar whitespace. It's merely to show string-part similarities
1433 Longworth House Office Building Washington, D.C. 20515
332 Cannon HOB Washington DC 20515
1641 LONGWORTH HOUSE OFFICE BUILDING WASHINGTON, DC 20515
1238 Cannon H.O.B. (line return)
Washington, DC 20515
8293 Longworth House Office Building • Washington DC • 20515
8293 Longworth House Office Building | Washington DC | 20515
Each of these will come back individually surrounded by tons of other text and html tags. The addresses may even contain an <br> or <br/> within the address itself.
What I would like to do is capture the first match from the source string, and set it as the value of a variable. From my understanding, this would best be approached with a regular-expression.
Update:
After learning more about the various ways in which these days can appear, I've decided that a less-strict expression would be best. These addresses have been showing up with bullets, pipes, and newlines. Perhaps an expression that communicates the following would be best:
[numbers][anything]["washington"][anything][DC|D.C.][anything][five numbers]
Apparently that is way too loose. The anything blocks were bringing in paragraphs, when I'm merely interested in allowing a few chars of anything.
So far I've been unsuccessful at matching the addresses found on the following (these are just a few of the many)