I have come across a number of situations where I want to plot more points than I really ought to be -- the main holdup is that when I share my plots with people or embed them in papers, they occupy too much space. It's very straightforward to randomly sample rows in a dataframe.
if I want a truly random sample for a point plot, it's easy to say:
ggplot(x,y,data=myDf[sample(1:nrow(myDf),1000),])
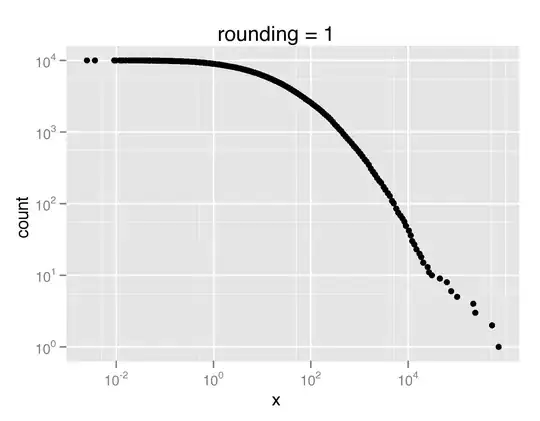
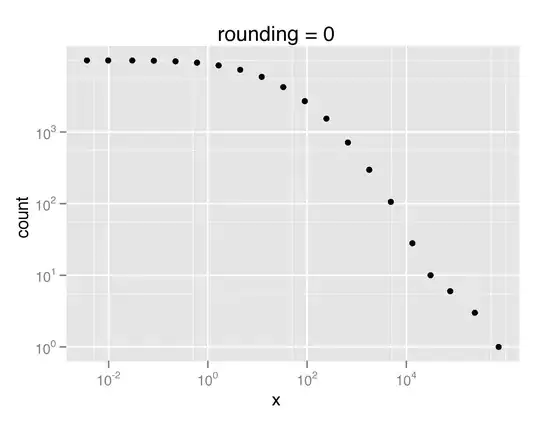
However, I was wondering if there were more effective (ideally canned) ways to specify the number of plot points such that your actual data is accurately reflected in the plot. So here is an example. Suppose I am plotting something like the CCDF of a heavy tailed distribution, e.g.
ccdf <- function(myList,density=FALSE)
{
# generates the CCDF of a list or vector
freqs = table(myList)
X = rev(as.numeric(names(freqs)))
Y =cumsum(rev(as.list(freqs)));
data.frame(x=X,count=Y)
}
qplot(x,count,data=ccdf(rlnorm(10000,3,2.4)),log='xy')
This will produce a plot where the x & y axis become increasingly dense. Here it would be ideal to have fewer samples plotted for large x or y values.
Does anybody have any tips or suggestions for dealing with similar issues?
Thanks, -e