Take a look for yourself. For future reference, you can just google:
java LinkedHashMap source
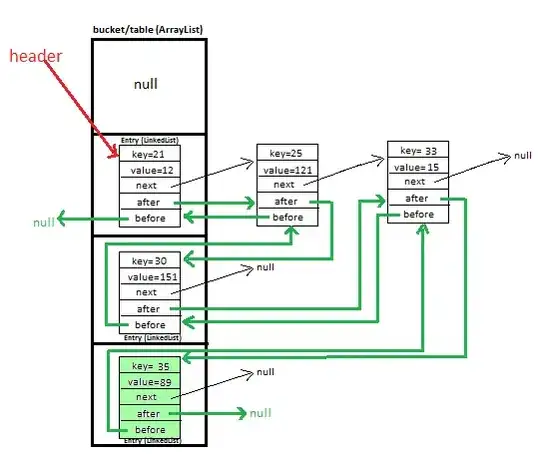
HashMap uses a LinkedList to handle collissions, but the difference between HashMap and LinkedHashMap is that LinkedHashMap has a predicable iteration order, which is achieved through an additional doubly-linked list, which usually maintains the insertion order of the keys. The exception is when a key is reinserted, in which case it goes back to the original position in the list.
For reference, iterating through a LinkedHashMap is more efficient than iterating through a HashMap, but LinkedHashMap is less memory efficient.
In case it wasn't clear from my above explanation, the hashing process is the same, so you get the benefits of a normal hash, but you also get the iteration benefits as stated above, since you're using a doubly linked list to maintain the ordering of your Entry objects, which is independent of the linked-list used during hashing for collisions, in case that was ambiguous..
EDIT: (in response to OP's comment):
A HashMap is backed by an array, in which some slots contain chains of Entry objects to handle the collisions. To iterate through all of the (key,value) pairs, you would need to go through all of the slots in the array and then go through the LinkedLists; hence, your overall time would be proportional to the capacity.
When using a LinkedHashMap, all you need to do is traverse through the doubly-linked list, so the overall time is proportional to the size.