According to the answer by @Jens Timmerman on this post: Extract the first paragraph from a Wikipedia article (Python)
i did this:
import urllib2
def getPage(url):
opener = urllib2.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')] #wikipedia needs this
resource = opener.open("http://en.wikipedia.org/wiki/" + url)
data = resource.read()
resource.close()
return data
print getPage('Steve_Jobs')
technically it should run properly and give me the source of the page. but here's what i get:
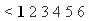
any help would be appreciated..