First of all, some algorithms converge even with zero initial weightings. A simple example is a Linear Perceptron Network. Of course, many learning networks require random initial weighting (although this is not a guarantee of getting the fastest and best answer).
Neural networks use Back-propagation to learn and to update weights, and the problem is that in this method, weights converge to the local optimal (local minimum cost/loss), not the global optimal.
Random weighting helps the network to take chances for each direction in the available space and gradually improve them to arrive at a better answer and not be limited to one direction or answer.
[The image below shows a one-dimensional example of how convergence. Given the initial location, local optimization is achieved but not a global optimization. At higher dimensions, random weighting can increase the chances of being in the right place or starting better, resulting in converging weights to better values.][1]
[1]: https://i.stack.imgur.com/2dioT.png [Kalhor, A. (2020). Classification and Regression NNs. Lecture.]
In the simplest case, the new weight is as follows:
W_new = W_old + D_loss
Here the cost function gradient is added to the previous weight to get a new weight. If all the previous weights are the same, then in the next step all the weights may be equal. As a result, in this case, from a geometric point of view, the neural network is inclined in one direction and all weights are the same. But if the weights are different, it is possible to update the weights by different amounts. (depending on the impact factor that each weight has on the result, it affects the cost and the updates of the weights. So even a small error in the initial random weighting can be solved).
This was a very simple example, but it shows the effect of random weighting initialization on learning. This enables the neural network to go to different spaces instead of going to one side. As a result, in the process of learning, go to the best of these spaces
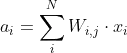

{kind=link}