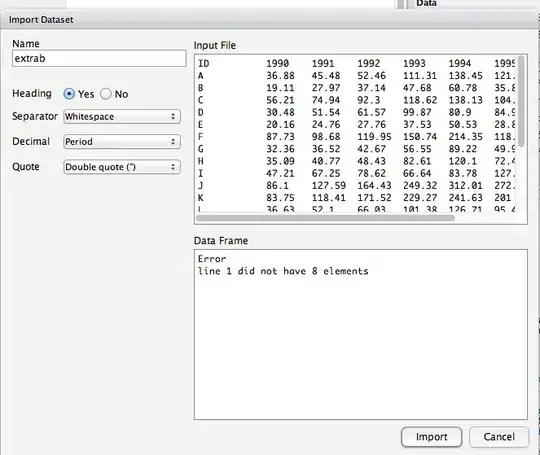
I'm having problem reading text file into R. The text file has 8 columns and a header which looks exactly like this:
ID 1990 1991 1992 1993 1994 1995 1996
A 36.88 45.48 52.46 111.31 138.45 121.09 122.62
B 19.11 27.97 37.14 47.68 60.78 35.84 38.64
C 56.21 74.94 92.3 118.62 138.13 104.65 113.98
D 30.48 51.54 61.57 99.87 80.9 84.97 99.34
When I do the following, I get the error
> extra<- read.table("extrab.txt", header=T, sep="\t")
Error in make.names(col.names, unique = TRUE) :
invalid multibyte string at '<ff><fe>I'
So I tried adding fileEnconding
> extra<- read.table("extrab.txt", header=T, sep="\t", fileEncoding="UCS-2LE")
This worked, but I ended up with a dataframe with one variable where ID to 1996 was treated as one column. Would there be a way to solve this?
I'm adding few more lines on this problem, because I found a different error when I tried to import the file through R