I have a file that is HTML, and it has about 150 anchor tags. I need only the links from these tags, AKA, <a href="*http://www.google.com*"></a>. I want to get only the http://www.google.com part.
When I run a grep,
cat website.htm | grep -E '<a href=".*">' > links.txt
this returns the entire line to me that it found on not the link I want, so I tried using a cut command:
cat drawspace.txt | grep -E '<a href=".*">' | cut -d’”’ --output-delimiter=$'\n' > links.txt
Except that it is wrong, and it doesn't work give me some error about wrong parameters... So I assume that the file was supposed to be passed along too. Maybe like cut -d’”’ --output-delimiter=$'\n' grepedText.txt > links.txt.
But I wanted to do this in one command if possible... So I tried doing an AWK command.
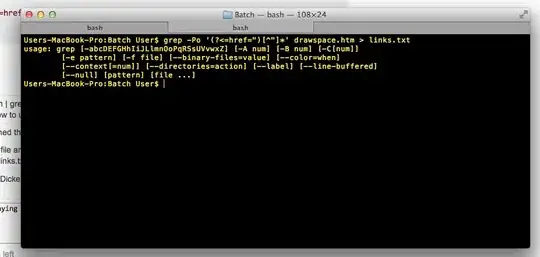
cat drawspace.txt | grep '<a href=".*">' | awk '{print $2}’
But this wouldn't run either. It was asking me for more input, because I wasn't finished....
I tried writing a batch file, and it told me FINDSTR is not an internal or external command... So I assume my environment variables were messed up and rather than fix that I tried installing grep on Windows, but that gave me the same error....
The question is, what is the right way to strip out the HTTP links from HTML? With that I will make it work for my situation.
P.S. I've read so many links/Stack Overflow posts that showing my references would take too long.... If example HTML is needed to show the complexity of the process then I will add it.
I also have a Mac and PC which I switched back and forth between them to use their shell/batch/grep command/terminal commands, so either or will help me.
I also want to point out I'm in the correct directory
HTML:
<tr valign="top">
<td class="beginner">
B03
</td>
<td>
<a href="http://www.drawspace.com/lessons/b03/simple-symmetry">Simple Symmetry</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B04
</td>
<td>
<a href="http://www.drawspace.com/lessons/b04/faces-and-a-vase">Faces and a Vase</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B05
</td>
<td>
<a href="http://www.drawspace.com/lessons/b05/blind-contour-drawing">Blind Contour Drawing</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B06
</td>
<td>
<a href="http://www.drawspace.com/lessons/b06/seeing-values">Seeing Values</a> </td>
</tr>
Expected output:
http://www.drawspace.com/lessons/b03/simple-symmetry
http://www.drawspace.com/lessons/b04/faces-and-a-vase
http://www.drawspace.com/lessons/b05/blind-contour-drawing
etc.