Context is an Oracle Database, Entity Framework 5, LinqToEntities, Database First.
I'm trying to implement pagination over some large tables, my linqToEntities query looks like this :
context.MyDbSet
.Include("T2")
.Include("T3")
.Include("T4")
.Include("T5")
.Include("T6")
.Where(o => o.T3 != null)
.OrderBy(o => o.Id)
.Skip(16300)
.Take(50);
Fact is, depending on how many records i wanna skip (0 or 16300) it goes from 0.08s to 10.7s.
It seems weird to me so i checked the generated SQL and here is how it looks like :
SELECT *
FROM (
SELECT
[...]
FROM ( SELECT [...] row_number() OVER (ORDER BY "Extent1"."Id" ASC) AS "row_number"
FROM T1 "Extent1"
LEFT OUTER JOIN T2 "Extent2" ON [...]
LEFT OUTER JOIN T3 "Extent3" ON [...]
LEFT OUTER JOIN T4 "Extent4" ON [...]
LEFT OUTER JOIN T5 "Extent5" ON [...]
LEFT OUTER JOIN T6 "Extent6" ON [...]
WHERE ("Extent1"."SomeId" IS NOT NULL)
) "Filter1"
WHERE ("Filter1"."row_number" > 16300)
ORDER BY "Filter1"."Id" ASC
)
WHERE (ROWNUM <= (50) )
I checked if it actually was Oracle who took time through SQL Developper, and it is.
I then checked the execution plan and it's what appears :
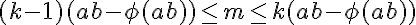
All i actually understand is that there's no STOPKEY for the first filter over row_number and that it probably fetch the whole sub query.
I don't really know where to look at, if i'm not mistaken, the request is generated by ODT/ODP/.. and thus, should be optimized for an Oracle DB.. (and i can't change it myself)
Maybe my database model is rotten and i could add whetever indexes or optimization for it to work better ?