How to find all "cat"s with a regular expressions?
"Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems!" (c) Jamie Zawinski
Help me please to find all "cat"s in divs with a single query :)
cat
<div>let's try to find this cat and this cat</div>
cat
<div>let's try to find this cat and this cat</div>
cat
I had do this, but it's not working:
(?<=<div>)((?!<\/div>)(cat|(?:.|\n))+)(?=<\/div>)
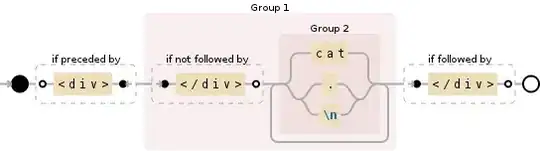
I found this problem when i used Sublime Text. We can make only one query. Is it possible? If you can answer using any programming languages (Python, PHP, JavaScript), i'll be glad too. Thank you!
I can find the last cat, or the first one, but need to find all the cats that sit in some DIVs. I suppose it may be possible with other languages stuff, but i want only one query (one line) - it's most interesting for me. If it's not possible, sorry for my post :)
Thanks to @revo! Very nice variant, that works in Sublime Text. Let me add 2nd question for this theme... Сan we do it for divs with class "cats", but not for divs with class "dogs"?
cat
<div class="cats">black cat, white cat</div>
cat
<div class="dogs">black cat, white cat</div>
cat