Based on my previous question:
I'm still trying to copy an image (no practical reason, just to start with an easy one):
The image contains 200 * 300 == 60000 pixels.
The maximum number of work-items is 4100 according to CL_DEVICE_MAX_WORK_GROUP_SIZE.
kernel1:
std::string kernelCode =
"void kernel copy(global const int* image, global int* result)"
"{"
"result[get_local_id(0) + get_group_id(0) * get_local_size(0)] = image[get_local_id(0) + get_group_id(0) * get_local_size(0)];"
"}";
queue:
for (int offset = 0; offset < 30; ++offset)
queue.enqueueNDRangeKernel(imgProcess, cl::NDRange(offset * 2000), cl::NDRange(60000));
queue.finish();
Gives segfault, what's wrong?
With the last parameter cl::NDRange(20000) it doesn't, but gives back only part of the image.
Also I don't understand, why I can't use this kernel:
kernel2:
std::string kernelCode =
"void kernel copy(global const int* image, global int* result)"
"{"
"result[get_global_id(0)] = image[get_global_id(0)];"
"}";
Looking at this presentation on the 31th slide:
Why can't I just simply use the global_id?
EDIT1
Platfrom: AMD Accelerated Parallel Processing
Device: AMD Athlon(tm) II P320 Dual-Core Processor
EDIT2
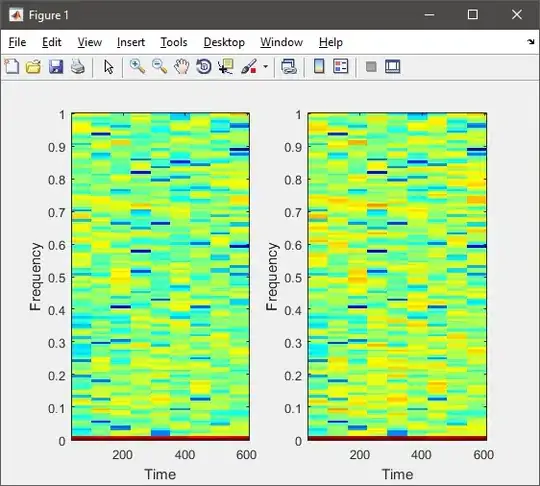
The result based on huseyin tugrul buyukisik's answer:
EDIT3
With the last parameter cl::NDRange(20000):
Kernel is both ways the first one.
EDIT4
std::string kernelCode =
"void kernel copy(global const int* image, global int* result)"
"{"
"result[get_global_id(0)] = image[get_global_id(0)];"
"}";
//...
cl_int err;
err = queue.enqueueNDRangeKernel(imgProcess, cl::NDRange(0), cl::NDRange(59904), cl::NDRange(128));
if (err == 0)
qDebug() << "success";
else
{
qDebug() << err;
exit(1);
}
Prints success.
Maybe this is wrong?
int size = _originalImage.width() * _originalImage.height();
int* result = new int[size];
//...
cl::Buffer resultBuffer(context, CL_MEM_READ_WRITE, size);
//...
queue.enqueueReadBuffer(resultBuffer, CL_TRUE, 0, size, result);
The guilty was:
cl::Buffer imageBuffer(context, CL_MEM_USE_HOST_PTR, sizeof(int) * size, _originalImage.bits());
cl::Buffer resultBuffer(context, CL_MEM_READ_ONLY, sizeof(int) * size);
queue.enqueueReadBuffer(resultBuffer, CL_TRUE, 0, sizeof(int) * size, result);
I used size instead of sizeof(int) * size.