i have the variable 'actorslist' and its output 100 lines of this ( a line for each movie):
[u'Tim Robbins', u'Morgan Freeman', u'Bob Gunton', u'William Sadler']
[u'Christian Bale', u'Heath Ledger', u'Aaron Eckhart', u'Michael Caine']
etc.
Then I have:
pairslist = list(itertools.permutations(actorslist, 2))
This gives me the pairs of actors, but only within a specific movie and then after a new line it goes to the next movie. How can I get it to output all the actors from all the movies in one big array? The idea being that two actors who were in a movie together should get a pydot edge.
I put in this, which successfully outputted to a dot file, but isn't outputting the right data.
graph = pydot.Dot(graph_type='graph', charset="utf8")
for i in pairslist:
edge = pydot.Edge(i[0], i[1])
graph.add_edge(edge)
graph.write('dotfile.dot')
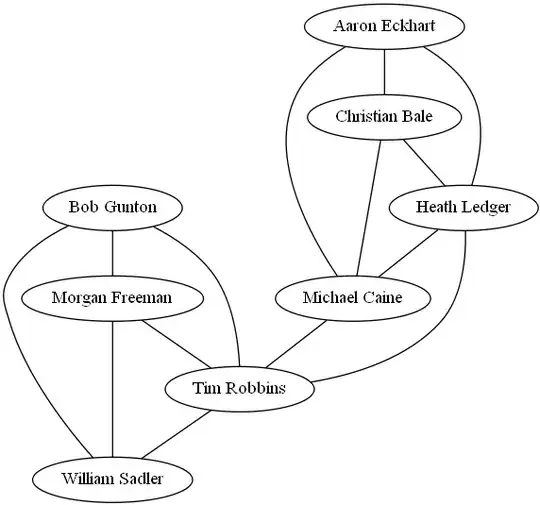
My expected output should be as follows in the dot file (A,B) is the same as (B,A) and so don't exist in the output:
"Tim Robbins" -- "Morgan Freeman";
"Tim Robbins" -- "Bob Gunton";
"Tim Robbins" -- "William Sadler";
"Morgan Freeman" -- "Bob Gunton";
"Morgan Freeman" -- "William Sadler";
"Bob Gunton" -- "William Sadler";
"Christian Bale" -- "Heath Ledger";
"Christian Bale" -- "Aaron Eckhart";
"Christian Bale" -- "Michael Caine";
"Heath Ledger" -- "Aaron Eckhart";
"Heath Ledger" -- "Michael Caine";
"Aaron Eckhart" -- "Michael Caine";
ADDITIONAL INFO:
some were interested in how the variable actorslist was created:
file = open('input.txt','rU') ###input is JSON data on each line{"Title":"Shawshank...
nfile = codecs.open('output.txt','w','utf-8')
movie_actors = []
for line in file:
line = line.rstrip()
movie = json.loads(line)
l = []
title = movie['Title']
actors = movie['Actors']
tempactorslist = actors.split(',')
actorslist = []
for actor in tempactorslist:
actor = actor.strip()
actorslist.append(actor)
l.append(title)
l.append(actorslist)
row = l[0] + '\t' + json.dumps(l[1]) + '\n'
nfile.writelines(row)