I am using elasticsearch-py to connect to my ES database which contains over 3 million documents. I want to return all the documents so I can abstract data and write it to a csv. I was able to accomplish this easily for 10 documents (the default return) using the following code.
es=Elasticsearch("glycerin")
query={"query" : {"match_all" : {}}}
response= es.search(index="_all", doc_type="patent", body=query)
for hit in response["hits"]["hits"]:
print hit
Unfortunately, when I attempted to implement the scan & scroll so I could get all the documents I ran into issues. I tried it two different ways with no success.
Method 1:
scanResp= es.search(index="_all", doc_type="patent", body=query, search_type="scan", scroll="10m")
scrollId= scanResp['_scroll_id']
response= es.scroll(scroll_id=scrollId, scroll= "10m")
print response
 After
After scroll/ it gives the scroll id and then ends with ?scroll=10m (Caused by <class 'httplib.BadStatusLine'>: ''))
Method 2:
query={"query" : {"match_all" : {}}}
scanResp= helpers.scan(client= es, query=query, scroll= "10m", index="", doc_type="patent", timeout="10m")
for resp in scanResp:
print "Hiya"
If I print out scanResp before the for loop I get <generator object scan at 0x108723dc0>. Because of this I'm relatively certain that I'm messing up my scroll somehow, but I'm not sure where or how to fix it.
Results:
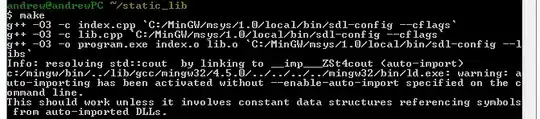 Again, after
Again, after scroll/ it gives the scroll id and then ends with ?scroll=10m (Caused by <class 'httplib.BadStatusLine'>: ''))
I tried increasing the Max retries for the transport class, but that didn't make a difference.I would very much appreciate any insight into how to fix this.
Note: My ES is located on a remote desktop on the same network.