The first attempt
I defined functions regularmultiply() and bitwisemultiply() as follows:
int regularmultiply(int j)
{
return j * 2.25;
}
int bitwisemultiply(int k)
{
return (k << 1) + (k >> 2);
}
Upon doing profiling with Instruments (in XCode on a 2009 Macbook OS X 10.9.2), it seemed that bitwisemultiply executed about 2x faster than regularmultiply.
The assembly code output seemed to confirm this, with bitwisemultiply spending most of its time on register shuffling and function returns, while regularmultiply spent most of its time on the multiplying.
regularmultiply:
bitwisemultiply:
But the length of my trials was too short.
The second attempt
Next, I tried executing both functions with 10 million multiplications, and this time putting the loops in the functions so that all the function entry and leaving wouldn't obscure the numbers. And this time, the results were that each method took about 52 milliseconds of time. So at least for a relatively large but not gigantic number of calculations, the two functions take about the same time. This surprised me, so I decided to calculate for longer and with larger numbers.
The third attempt
This time, I only multiplied 100 million through 500 million by 2.25, but the bitwisemultiply actually came out slightly slower than the regularmultiply.
The final attempt
Finally, I switched the order of the two functions, just to see if the growing CPU graph in Instruments was perhaps slowing the second function down. But still, the regularmultiply performed slightly better:
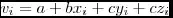
Here is what the final program looked like:
#include <stdio.h>
int main(void)
{
void regularmultiplyloop(int j);
void bitwisemultiplyloop(int k);
int i, j, k;
j = k = 4;
bitwisemultiplyloop(k);
regularmultiplyloop(j);
return 0;
}
void regularmultiplyloop(int j)
{
for(int m = 0; m < 10; m++)
{
for(int i = 100000000; i < 500000000; i++)
{
j = i;
j *= 2.25;
}
printf("j: %d\n", j);
}
}
void bitwisemultiplyloop(int k)
{
for(int m = 0; m < 10; m++)
{
for(int i = 100000000; i < 500000000; i++)
{
k = i;
k = (k << 1) + (k >> 2);
}
printf("k: %d\n", k);
}
}
Conclusion
So what can we say about all this? One thing we can say for certain is that optimizing compilers are better than most people. And furthermore, those optimizations show themselves even more when there are a lot of computations, which is the only time you'd really want to optimize anyway. So unless you're coding your optimizations in assembly, changing multiplication to bit shifting probably won't help much.
It's always good to think about efficiency in your applications, but the gains of micro-efficiency are usually not enough to warrant making your code less readable.