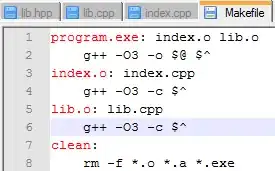
I am analyzing an image of two crossing lines (like a + sign) and I am extracting a line of pixels (an nx1 numpy array) perpendicular to one of the lines. This gives me an array of floating point values (representing colors) that I can then plot. I am plotting the data with matplotlib and I get a bunch of noisy data between 180 and 200 with a distinct peak in the middle that spikes down to around 100.
I need to find FWHM of this data. I figured I needed to filter the noise first, so I used a gaussian filter, which smoothed out my data, but its still not super flat at the top.
I was wondering if there is a better way to filter the data.
How can I find the FWHM of this data?
I would like to only use numpy, scipy, and matplotlib if possible.
Here is the original data:

Here is the filtered data: