I am having trouble with the speed of the search function that I wrote. The function steps are described below:
- The function begins with two table name parameters, a starting-point and a target
- The function then traverses a list of table-column combinations (50,000 long) and retrieves all the combinations associated with the starting-point table.
- The function then loops through each of the retrieved combinations and for each combination, it traverses the table-column combinations list once again, but this time looking for tables that match the given column.
- Finally, the function loops through each of the retrieved combinations from the last step and for each combination, it checks whether the table is the same as the target table; if so it saves it, and if not it calls itself passing in the table name form that combination.
The function aim is to be able to trace a link between tables where the link is direct or has multiple degrees of separation. The level of recursion is a fixed integer value.
My problem is that any time I try to run this function for two levels of search depth (wouldn't dare try deeper at this stage), the job runs out of memory, or I lose patience. I waited for 17mins before the job ran out of memory once.
The average number of columns per table is 28 and the standard deviation is 34.
Here is a diagram showing examples of the various links that can be made between tables:
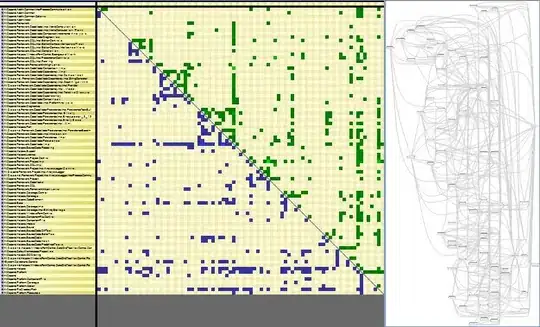
Here is my code:
private void FindLinkingTables(List<TableColumns> sourceList, TableSearchNode parentNode, string targetTable, int maxSearchDepth)
{
if (parentNode.Level < maxSearchDepth)
{
IEnumerable<string> tableColumns = sourceList.Where(x => x.Table.Equals(parentNode.Table)).Select(x => x.Column);
foreach (string sourceColumn in tableColumns)
{
string shortName = sourceColumn.Substring(1);
IEnumerable<TableSearchNode> tables = sourceList.Where(
x => x.Column.Substring(1).Equals(shortName) && !x.Table.Equals(parentNode.Table) && !parentNode.Ancenstory.Contains(x.Table)).Select(
x => new TableSearchNode { Table = x.Table, Column = x.Column, Level = parentNode.Level + 1 });
foreach (TableSearchNode table in tables)
{
parentNode.AddChildNode(sourceColumn, table);
if (!table.Table.Equals(targetTable))
{
FindLinkingTables(sourceList, table, targetTable, maxSearchDepth);
}
else
{
table.NotifySeachResult(true);
}
}
}
}
}
EDIT: separated out TableSearchNode logic and added property and method for completeness
//TableSearchNode
public Dictionary<string, List<TableSearchNode>> Children { get; private set; }
//TableSearchNode
public List<string> Ancenstory
{
get
{
Stack<string> ancestory = new Stack<string>();
TableSearchNode ancestor = ParentNode;
while (ancestor != null)
{
ancestory.Push(ancestor.tbl);
ancestor = ancestor.ParentNode;
}
return ancestory.ToList();
}
}
//TableSearchNode
public void AddChildNode(string referenceColumn, TableSearchNode childNode)
{
childNode.ParentNode = this;
List<TableSearchNode> relatedTables = null;
Children.TryGetValue(referenceColumn, out relatedTables);
if (relatedTables == null)
{
relatedTables = new List<TableSearchNode>();
Children.Add(referenceColumn, relatedTables);
}
relatedTables.Add(childNode);
}
Thanks in advance for your help!