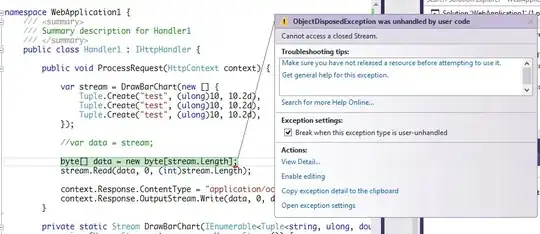
I'm iterating over a large csv file and I'd like to print out some progress indicator. As I understand counting the number of lines would requires parsing all of the file for newline characters. So I cannot easily estimate progress with line number.
Is there anything else I can do to estimate the progress while reading in lines? Maybe I can go by size?