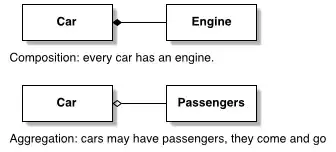
I have rows in a list that are sometimes similar up to the first "space" character, then can change (i.e. a date afterwards).
wsmith jul/12/12
bwillis jul/13/13
wsmith jul/14/12
tcruise jul/12/12
I can easily sort the lines, but I'd love to remove the duplicate later dated entry. I did find a regex suggestion, but it matches only exactly the same lines. I need to be able to mark the entire row of similar usernames in the file. In my example above, lines 1 and 3 would be highlighted.
(edited for clarity)